

It is a known good practice to keep only necessary indexes to reduce the write performance and disk space overhead. This simple rule is mentioned briefly in the official MySQL Documentation:
https://dev.mysql.com/doc/refman/8.0/en/optimization-indexes.html
However, in some cases, the overhead from adding a new index can be way above the expectations! Recently, I’ve been analyzing a customer case like that, and it encouraged me to share this kind of example as it surely may be surprising for many developers and even DBAs.
Let’s take this pretty specific table example, which has only three columns. The primary key is created on two of them:
1 2 3 4 5 6 7 8 9 10 | mysql > show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `a` varchar(32) NOT NULL, `b` int unsigned NOT NULL, `c` varchar(32) NOT NULL, PRIMARY KEY (`a`,`c`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec) |
With this schema, the table having 5M random rows has these statistics (note the Index_lenght):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | mysql > show table status like 't1'\G *************************** 1. row *************************** Name: t1 Engine: InnoDB Version: 10 Row_format: Dynamic Rows: 4969944 Avg_row_length: 104 Data_length: 521125888 Max_data_length: 0 Index_length: 0 Data_free: 2097152 Auto_increment: NULL Create_time: 2024-01-22 22:39:52 Update_time: NULL Check_time: NULL Collation: utf8mb4_0900_ai_ci Checksum: NULL Create_options: Comment: 1 row in set (0.01 sec) |
The size on disk (table was optimized to rule out fragmentation):
1 2 | $ ls -lh db1/t1.ibd -rw-r----- 1 przemek przemek 508M Jan 22 22:40 db1/t1.ibd |
When our queries use column b in the WHERE clause, it is natural that we have to optimize such query by adding an index to the column to avoid this kind of bad execution (i.e., full table scan):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | mysql > EXPLAIN select * from t1 where b=10\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 4976864 filtered: 0.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) |
So, we add the index:
1 2 3 | mysql > alter table t1 add key(b); Query OK, 0 rows affected (38.68 sec) Records: 0 Duplicates: 0 Warnings: 0 |
And the query is very fast now. However, the table size increased by 400 MB!
1 2 | $ ls -lh db1/t1.ibd -rw-r----- 1 przemek przemek 908M Jan 22 23:11 db1/t1.ibd |
You’d ask — how is it possible that adding an index on one small INT column made that huge growth? The table size increased by +79%, totally not expected given we only indexed the smallest column in the table!
Would you be surprised if I told you that I actually expected it to grow even more? The reason is that a secondary index has the primary key columns appended to its records. Let me quote the documentation here:
In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index.
If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
Therefore, in this table case, a new index will contain all three columns, effectively duplicating all table values! Before the change, there was only the clustered (primary) index, which holds the whole row data (both its defined columns and the other column(s). The new index on column b includes this column plus columns defined as primary key, so again, all three columns in this specific table case. Therefore, I expected the table to double its size. Let’s investigate why this did not happen and why the table space file did not grow to ~1GB.
With the help of the innodb_ruby tool, I checked the index statistics before the ALTER:
1 2 3 4 | $ innodb_space -f db1/t1.ibd space-indexes id name root fseg fseg_id used allocated fill_factor 314 4 internal 3 132 159 83.02% 314 4 leaf 4 27680 31648 87.46% |
To find out what is the index with id=314, we can use this query:
1 2 3 4 5 6 7 8 | mysql > select SPACE,INDEX_ID,i.NAME as index_name, t.NAME as table_name,FILE_SIZE from information_schema.INNODB_INDEXES i JOIN information_schema.INNODB_TABLESPACES t USING(space) WHERE t.NAME='db1/t1'\G *************************** 1. row *************************** SPACE: 15 INDEX_ID: 314 index_name: PRIMARY table_name: db1/t1 FILE_SIZE: 532676608 1 row in set (0.00 sec) |
So there are ~32k allocated pages in the table. The tool lets you get into many details about the InnoDB tablespace, for example, what is the per page usage, i.e.:
1 2 3 4 5 6 7 8 9 10 11 | $ innodb_space -f db1/t1.ibd space-index-pages-summary|head -10 page index level data free records 4 314 2 9371 6819 131 5 314 0 15105 1055 189 6 314 0 15101 1063 183 7 314 1 15060 1088 214 8 314 0 15058 1104 184 9 314 0 15121 1041 184 10 314 0 15118 1044 184 11 314 0 15063 1101 180 12 314 0 15072 1092 180 |
After adding the secondary index, we can see more details about how the new index compares with the primary key:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | mysql > show table status like 't1'\G *************************** 1. row *************************** Name: t1 Engine: InnoDB Version: 10 Row_format: Dynamic Rows: 4981016 Avg_row_length: 104 Data_length: 521125888 Max_data_length: 0 Index_length: 413122560 Data_free: 4194304 Auto_increment: NULL Create_time: 2024-01-22 23:11:19 Update_time: NULL Check_time: NULL Collation: utf8mb4_0900_ai_ci Checksum: NULL Create_options: Comment: 1 row in set (0.00 sec) |
1 2 3 4 5 6 | $ innodb_space -f db1/t1.ibd space-indexes id name root fseg fseg_id used allocated fill_factor 314 4 internal 3 132 159 83.02% 314 4 leaf 4 27680 31648 87.46% 315 39 internal 5 104 159 65.41% 315 39 leaf 6 21914 25056 87.46% |
The index 315 is the secondary on column “b”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | mysql > select SPACE,INDEX_ID,i.NAME as index_name, t.NAME as table_name,FILE_SIZE from information_schema.INNODB_INDEXES i JOIN information_schema.INNODB_TABLESPACES t USING(space) WHERE t.NAME='db1/t1'\G *************************** 1. row *************************** SPACE: 15 INDEX_ID: 314 index_name: PRIMARY table_name: db1/t1 FILE_SIZE: 952107008 *************************** 2. row *************************** SPACE: 15 INDEX_ID: 315 index_name: b table_name: db1/t1 FILE_SIZE: 952107008 2 rows in set (0.01 sec) |
And we can see it has fewer total pages allocated, around 25k, vs 32k the PK has. So why does the clustered index need more pages to hold the same data values? The index summary shows the difference between the two:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | $ innodb_space -f db1/t1.ibd space-index-pages-summary page index level data free records (...) 6327 314 0 15057 1107 181 6328 314 0 15138 1026 180 6329 314 0 15128 1038 178 6330 314 0 15134 1032 178 6331 314 0 15135 1031 179 6332 314 0 15071 1095 179 6333 314 0 15092 1072 180 6334 314 0 15072 1094 179 6335 314 0 15115 1051 179 6336 314 1 15064 1086 211 6337 314 1 15098 1052 210 6338 314 1 15112 1038 211 6339 314 1 15119 1029 212 6340 315 0 16072 70 227 6341 315 0 16135 5 228 6342 315 1 16132 16 215 6343 315 0 16118 22 228 6344 315 0 16097 45 226 6345 315 0 16074 66 229 6346 315 0 16093 47 229 6347 315 0 16091 49 228 6348 315 0 16073 69 227 6349 315 0 16092 48 230 6350 315 0 16095 45 228 6351 315 0 16133 9 227 6352 315 0 16126 14 230 |
The innodb_ruby tool allows us to see that the secondary index (id 315) is able to store more records on one page as compared to the clustered index (id 314). The latter leaves more free space per page. This explains why duplicating values did not exactly cause duplicating the table space size. The tool allows us to illustrate this nicely, using GNUplot:
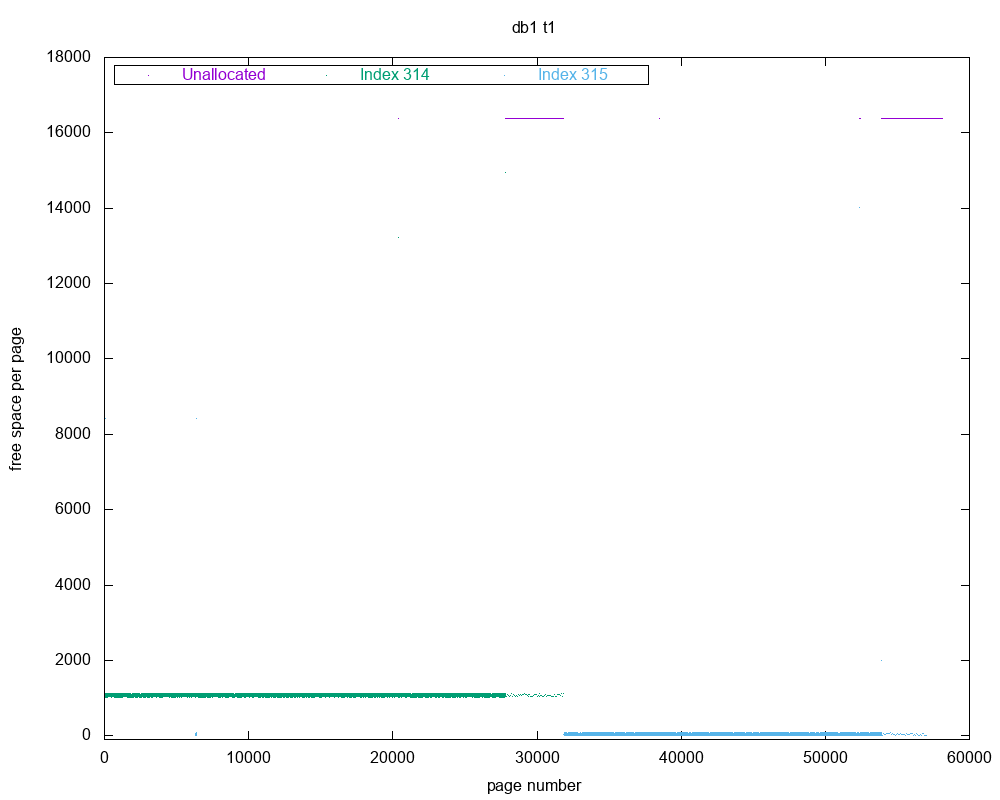
One important side effect of copying primary key values is that column b’s index is a covering one in our table case!
This is why we can see Using index in the extra info, even though the index is on one column only:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | mysql > EXPLAIN select * from t1 where b=10\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ref possible_keys: b key: b key_len: 4 ref: const rows: 1 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec) |
A conclusion from this is we want smaller primary keys if possible. Let’s modify this table accordingly:
1 2 3 | mysql > alter table t1 drop primary key, add column id int primary key auto_increment; Query OK, 0 rows affected (16.66 sec) Records: 0 Duplicates: 0 Warnings: 0 |
This reduces the table size from 908M to:
1 2 | $ ls -lh db1/t1.ibd -rw-r----- 1 przemek przemek 608M Jan 23 19:12 db1/t1.ibd |
(The disk space was automatically reclaimed because changing the primary key effectively re-creates the table.)
But it does not make much sense if other queries filter via columns a and c, as we’d need to add another index to satisfy them, which would amplify the overall size even more due to the large size of those columns:
1 2 3 | mysql > alter table t1 add key a_c(a,c); Query OK, 0 rows affected (45.33 sec) Records: 0 Duplicates: 0 Warnings: 0 |
1 2 | $ ls -lh db1/t1.ibd -rw-r----- 1 przemek przemek 1004M Jan 23 19:16 db1/t1.ibd |
On the other hand, this schema change will benefit other operations, like ROW replication (simple INT PK lookup vs compound varchar lookup), checksumming, etc. The modified table definition looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 | mysql > show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `a` varchar(32) NOT NULL, `b` int unsigned NOT NULL, `c` varchar(32) NOT NULL, `id` int NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`), KEY `b` (`b`), KEY `a_c` (`a`,`c`) ) ENGINE=InnoDB AUTO_INCREMENT=5001368 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec) |
The new index statistics reflect how the optimized primary key makes the same secondary index (id=323) size overhead way smaller – 4.7k pages instead of 25k pages:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | mysql > select SPACE,INDEX_ID,i.NAME as index_name, t.NAME as table_name,FILE_SIZE from information_schema.INNODB_INDEXES i JOIN information_schema.INNODB_TABLESPACES t USING(space) WHERE t.NAME='db1/t1'G *************************** 1. row *************************** SPACE: 19 INDEX_ID: 322 index_name: PRIMARY table_name: db1/t1 FILE_SIZE: 1052770304 *************************** 2. row *************************** SPACE: 19 INDEX_ID: 323 index_name: b table_name: db1/t1 FILE_SIZE: 1052770304 *************************** 3. row *************************** SPACE: 19 INDEX_ID: 324 index_name: a_c table_name: db1/t1 FILE_SIZE: 1052770304 3 rows in set (0.00 sec) |
1 2 3 4 5 6 7 8 | $ innodb_space -f db1/t1.ibd space-indexes id name root fseg fseg_id used allocated fill_factor 322 4 internal 3 27 27 100.00% 322 4 leaf 4 29003 33184 87.40% 323 5 internal 5 6 6 100.00% 323 5 leaf 6 4157 4768 87.19% 324 32354 internal 7 104 159 65.41% 324 32354 leaf 8 21913 25056 87.46% |
The above example is a bit not typical, but my goal was to remind of an often forgotten behavior of the InnoDB engine with respect to indexes. The overhead from adding secondary indexes is proportionally bigger the larger the primary key is! The differences in disk usage can be huge, so keep it in mind while designing your tables.
For the same reason, the pretty common practice of using UUIDs for primary keys will hurt the performance and overall cost of storing the data. In case there is a real need to use UUIDs, maybe you can implement the nice workarounds described here:
UUIDs are Popular, but Bad for Performance — Let’s Discuss
Storing UUID and Generated Columns
And cut the UUID overhead significantly!
I encourage you to check more details on good practices for choosing the primary key in these blog posts:
Illustrating Primary Key models in InnoDB and their impact on disk usage
Queries for Finding Poorly-Designed MySQL Schemas and How to Fix Them





