

On a recent engagement I worked with a customer who makes extensive use of UUID() values for their Primary Key and stores it as char(36), and their row count on this example table has grown to over 1 billion rows.
The table is INSERT-only (no UPDATEs or DELETEs), and the bulk of their retrieval are PK lookups. Lookups by PK were performing acceptably, but they were concerned with the space usage by the table as we were approaching 1TB (running with innodb_file_per_table=1 and Percona Server 5.5).
This schema model presents an increasing burden for backups since they use Percona XtraBackup, and so the question was asked: does their choice of an effectively random Primary Key based on UUID() impact their on-disk storage, and to what extent? And as a neat trick I show towards the end of this post how you can calculate the rate of fragmentation in your table on a regular basis if you’re so inclined. So read on!
For background, the more common approach for a Primary Key in InnoDB is one that uses an integer AUTO_INCREMENT value. One of the benefits of a PK AUTO_INCREMENT is that it allows InnoDB to add new entries at the end of the table, and keeps the BTREE index from having to be split at any point. More on this splitting reference in a moment. Note also that this blog post isn’t intended to promote one type of model over another, my goal is really to illustrate the impact your choice of PK will have on the data on disk.
A Primary Key serves multiple purposes in InnoDB:
- Ensures uniqueness between rows
- InnoDB saves row data on disk clustered by the Primary Key
- Depending on the type used and INSERT / UPDATE pattern used, either provides for a unfragmented or severely fragmented Primary Key
I wanted to profile three different Primary Key types:
- integer AUTO_INCREMENT – this key will consume 4 bytes
- binary(16) using Ordered UUID() – as per Karthik’s UUID()-optimised blog post
- char(36) using UUID() – what my customer was used
I then used the powerful tool innodb_space’s function space-lsn-age-illustrate (from Jeremy Cole’s innodb_ruby project) to plot the LSN (InnoDB’s Log Sequence Number, an always-incrementing value) pages from each table that uses the different Primary Keys via ASCII colour (so hot, right? Thanks Jeremy!!). For reference, the legend indicates that the darker the colour, the “older” the page’s updated version is (the LSN), while as you move across the colour spectrum to pink you’re looking at the most recently written LSN values. What I’m trying to illustrate is that when you use AUTO_INCREMENT or UUID() that has been modified to insert in an ascending order, you get virtually no page splits, and thus consume the minimal amount of database pages. On the left side you’re looking at the page IDs for this table, and the lower the number of pages consumed, the more efficiently packed the table’s data is within those pages.
This is an example of INSERT-only based on a Primary Key of AUTO_INCREMENT. Notice how the darker colours are heavy at the earliest pages and lighter as we get to writing out the higher number pages. Further this table finishes writing somewhere around 700 pages consumed.

Primary Key integer AUTO_INCREMENT
As we look at the optimised-UUID() INSERT pattern we see that it too has a very evenly distributed pattern with oldest pages at the start (lowest page IDs) and newest written pages at the end of the table. More pages are consumed however because the Primary Key is wider, so we end somewhere around 1,100 pages consumed.
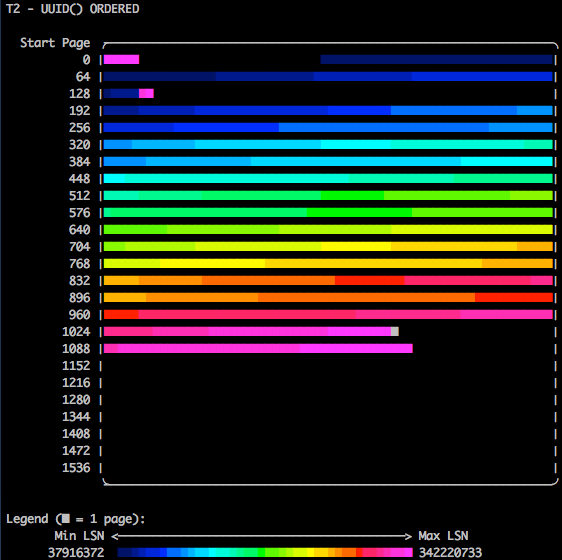
Ordered UUID()-based Primary Key
Finally we arrive at the UUID() INSERT pattern, and as we expected, the fragmentation is extreme and has caused many page splits — this is the behaviour in InnoDB when a record needs to be written into an existing page (since it falls between two existing values) and InnoDB realises that if this additional value is written that the capacity of the page will be overcommitted, so it then “splits” the page into two pages and writes them both out. The rash of pink in the image below shows us that UUID() causes significant fragmentation because it is causing pages to be split all throughout the table. This is deemed “expensive” since the ibd file now is more than 2x greater than the UUID()-optimised method, and about 3x greater than a Primary Key with AUTO_INCREMENT.
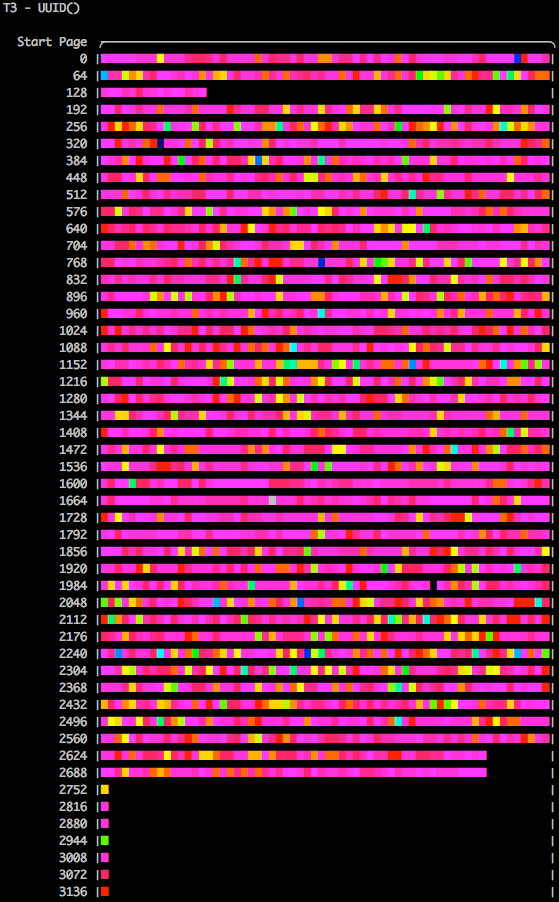
UUID() Primary Key
Based on this investigation we determined that the true size of the 1 billion row table was about half the size as reported by Linux when examining the .ibd file. We happened to have an opportunity to dump and load the table (mysqldump | mysql) and found that on restore the table consumed 450GB of disk — so our estimate was pretty good!
I also wanted to highlight that you can determine for yourself the statistics for data / pages split. As you can see below, the first two PK distributions are very tight, with pages packed up to 90%, however the UUID model leaves you with just slightly higher than 50%. You can run this against your prepared backups if you use Percona XtraBackup since at least version 2.1 by using the –stats option.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | [root@mysql]# xtrabackup --stats --datadir=/data/backups/mysql --target-dir=/data/backups/mysql | grep -A5 test | grep -A5 PRIMARY table: test/t1, index: PRIMARY, space id: 13, root page: 3, zip size: 0 estimated statistics in dictionary: key vals: 8, leaf pages: 99, size pages: 161 real statistics: level 1 pages: pages=1, data=1287 bytes, data/pages=7% leaf pages: recs=60881, pages=99, data=1461144 bytes, data/pages=90% -- table: test/t2_uuid_ordered, index: PRIMARY, space id: 14, root page: 3, zip size: 0 estimated statistics in dictionary: key vals: 8, leaf pages: 147, size pages: 161 real statistics: level 1 pages: pages=1, data=3675 bytes, data/pages=22% leaf pages: recs=60882, pages=147, data=2191752 bytes, data/pages=91% -- table: test/t3_uuid, index: PRIMARY, space id: 15, root page: 3, zip size: 0 estimated statistics in dictionary: key vals: 8, leaf pages: 399, size pages: 483 real statistics: level 2 pages: pages=1, data=92 bytes, data/pages=0% level 1 pages: pages=2, data=18354 bytes, data/pages=56% |
Below are the table definitions along with the scripts I used to generate the data for this post.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | mysql> show create table t1G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `c1` int(10) unsigned NOT NULL AUTO_INCREMENT, `c2` char(1) NOT NULL DEFAULT 'a', PRIMARY KEY (`c1`), KEY `c2` (`c2`) ) ENGINE=InnoDB AUTO_INCREMENT=363876 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) mysql> show create table t2_uuid_orderedG *************************** 1. row *************************** Table: t2_uuid_ordered Create Table: CREATE TABLE `t2_uuid_ordered` ( `pk` binary(16) NOT NULL, `c2` char(1) NOT NULL DEFAULT 'a', PRIMARY KEY (`pk`), KEY `c2` (`c2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec) mysql> show create table t3_uuidG *************************** 1. row *************************** Table: t3_uuid Create Table: CREATE TABLE `t3_uuid` ( `pk` char(36) NOT NULL, `c2` char(1) NOT NULL DEFAULT 'a', PRIMARY KEY (`pk`), KEY `c2` (`c2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec) |
1 2 3 4 5 6 7 | [root@mysql]# cat make_rows.sh #!/bin/bash while [ 1 ] ; do mysql -D test -e "insert into t1 (c2) values ('d')" ; mysql -D test -e "insert into t2_uuid_ordered (pk, c2) values (ordered_uuid(uuid()), 'a')" ; mysql -D test -e "insert into t3_uuid (pk, c2) values (uuid(), 'a')" ; done |
1 2 3 4 5 6 7 8 9 | [root@mysql]# cat space_lsn_age_illustrate.sh #!/bin/bash cd /var/lib/mysql echo "T1 - AUTO_INCREMENT" innodb_space -f test/t1.ibd space-lsn-age-illustrate echo "T2 - UUID() ORDERED" innodb_space -f test/t2_uuid_ordered.ibd space-lsn-age-illustrate echo "T3 - UUID()" innodb_space -f test/t3_uuid.ibd space-lsn-age-illustrate |
I hope that this post helps you to better understand the impact of random vs ordered Primary Key selection! Please share with me your thoughts on this post in the comments, thanks for reading!
Note to those attentive readers seeking more information: I plan to write a follow-up post that deals with these same models but from a performance perspective. In this post I tried to be as specific as possible with regards to the disk consumption and fragmentation concerns – I feel it addressed the first part and allude to this mysterious “fragmentation” beast but only teases at what that could mean for query response time… Just sit tight, I’m hopeful to get a tag-along to this one post-PLMCE!
By the way, come see me speak at the Percona Live MySQL Conference and Expo in Santa Clara, CA the week of April 13th – I’ll be delivering 5 talks and moderating one Keynote Panel. I hope to see you there! If you are at PLMCE, attend one my talks or stop me in the hallway and say “Hi Michael, I read your post, now where’s my beer?” – and I’ll buy you a cold one of your choice 🙂
- Keynote Panel: The next disruptive technology: “What comes after the Cloud and Big Data?”
- Main Conference – What I learned while migrating MySQL on-premises to Amazon RDS
- MySQL 101 & Main Conference – Running MySQL on AWS
- MySQL 101 – Percona Server Advantage (with Christopher Jeffus)
- MySQL 101 – MySQL & InnoDB Fundamentals & Configuration (with Justin Swanhart)





Brilliant blog, Michael! I have referenced your graphs several times to people asking about using UUID primary keys.
Hi @Bill Karwin, thanks for the kind words! It is great to see an older post still delivering value 🙂
very informative ! thank you !