

Update: do not do this, this has been proven to corrupt data!
During April’s Percona Live MySQL Conference and Expo 2014, I attended a talk on MySQL 5.7 performance an scalability given by Dimitri Kravtchuk, the Oracle MySQL benchmark specialist. He mentioned at some point that the InnoDB double write buffer was a real performance killer. For the ones that don’t know what the innodb double write buffer is, it is a disk buffer were pages are written before being written to the actual data file. Upon restart, pages in the double write buffer are rewritten to their data files if complete. This is to avoid data file corruption with half written pages. I knew it has an impact on performance, on ZFS since it is transactional I always disable it, but I never realized how important the performance impact could be. Back from PLMCE, a friend had dropped home a Dell R320 server, asking me to setup the OS and test it. How best to test a new server than to run benchmarks on it, so here we go!
ZFS is not the only transactional filesystem, ext4, with the option “data=journal”, can also be transactional. So, the question is: is it better to have the InnoDB double write buffer enabled or to use the ext4 transaction log. Also, if this is better, how does it compare with xfs, the filesystem I use to propose but which do not support transactions.
Methodology
The goal is to stress the double write buffer so the load has to be write intensive. The server has a simple mirror of two 7.2k rpm drives. There is no controller write cache and the drives write caches are disabled. I decided to use the Percona tpcc-mysql benchmark tool and with 200 warehouses, the total dataset size was around 18G, fitting all within the Innodb buffer pool (server has 24GB). Here’re the relevant part of the my.cnf:
1 2 3 4 5 6 7 8 9 10 11 | innodb_read_io_threads=4 innodb_write_io_threads=8 #To stress the double write buffer innodb_buffer_pool_size=20G innodb_buffer_pool_load_at_startup=ON innodb_log_file_size = 32M #Small log files, more page flush innodb_log_files_in_group=2 innodb_file_per_table=1 innodb_log_buffer_size=8M innodb_flush_method=O_DIRECT innodb_flush_log_at_trx_commit=0 skip-innodb_doublewrite #commented or not depending on test |
So, I generated the dataset for 200 warehouses, added they keys but not the foreign key constraints, loaded all that in the buffer pool with a few queries and dumped the buffer pool. Then, with MySQL stopped, I did a file level backup to a different partition. I used the MySQL 5.6.16 version that comes with Ubuntu 14.04, at the time Percona server was not available for 14.04. Each benchmark followed this procedure:
- Stop mysql
- umount /var/lib/mysql
- comment or uncomment skip-innodb_doublewrite in my.cnf
- mount /var/lib/mysql with specific options
- copy the reference backup to /var/lib/mysql
- Start mysql and wait for the buffer pool load to complete
- start tpcc from another server
The tpcc_start I used it the following:
1 | ./tpcc_start -h10.2.2.247 -P3306 -dtpcc -utpcc -ptpcc -w200 -c32 -r300 -l3600 -i60 |
I used 32 connections, let the tool run for 300s of warm up, enough to reach a steady level of dirty pages, and then, I let the benchmark run for one hour, reporting results every minute.
Results
| Test: | Double write buffer | File system options | Average NOPTM over 1h |
|---|---|---|---|
| ext4_dw | Yes | rw | 690 |
| ext4_dionolock_dw | Yes | rw,dioread_nolock | 668 |
| ext4_nodw | No | rw | 1107 |
| ext4trx_nodw | No | rw,data=journal | 1066 |
| xfs_dw | Yes | xfs rw,noatime | 754 |
So, from the above table, the first test I did was the common ext4 with the Innodb double write buffer enabled and it yielded 690 new order transactions per minute (NOTPM). Reading the ext4 doc, I also wanted to try the “dioread_nolock” setting that is supposed to reduce mutex contention and this time, I got slightly less 668 NOTPM. The difference is within the measurement error and isn’t significant. Removing the Innodb double write buffer, although unsafe, boosted the throughput to 1107 NOTPM, a 60% increase! Wow, indeed the double write buffer has a huge impact. But what is the impact of asking the file system to replace the innodb double write buffer? Surprisingly, the performance level is only slightly lower at 1066 NOTPM and vmstat did report twice the amount writes. I needed to redo the tests a few times to convince myself. Getting a 55% increase in performance with the same hardware is not common except when some trivial configuration errors are made. Finally, I used to propose xfs with the Innodb double write buffer enabled to customers, that’s about 10% higher than ext4 with the Innodb double write buffer, close to what I was expecting. The graphic below presents the numbers in a more visual form.
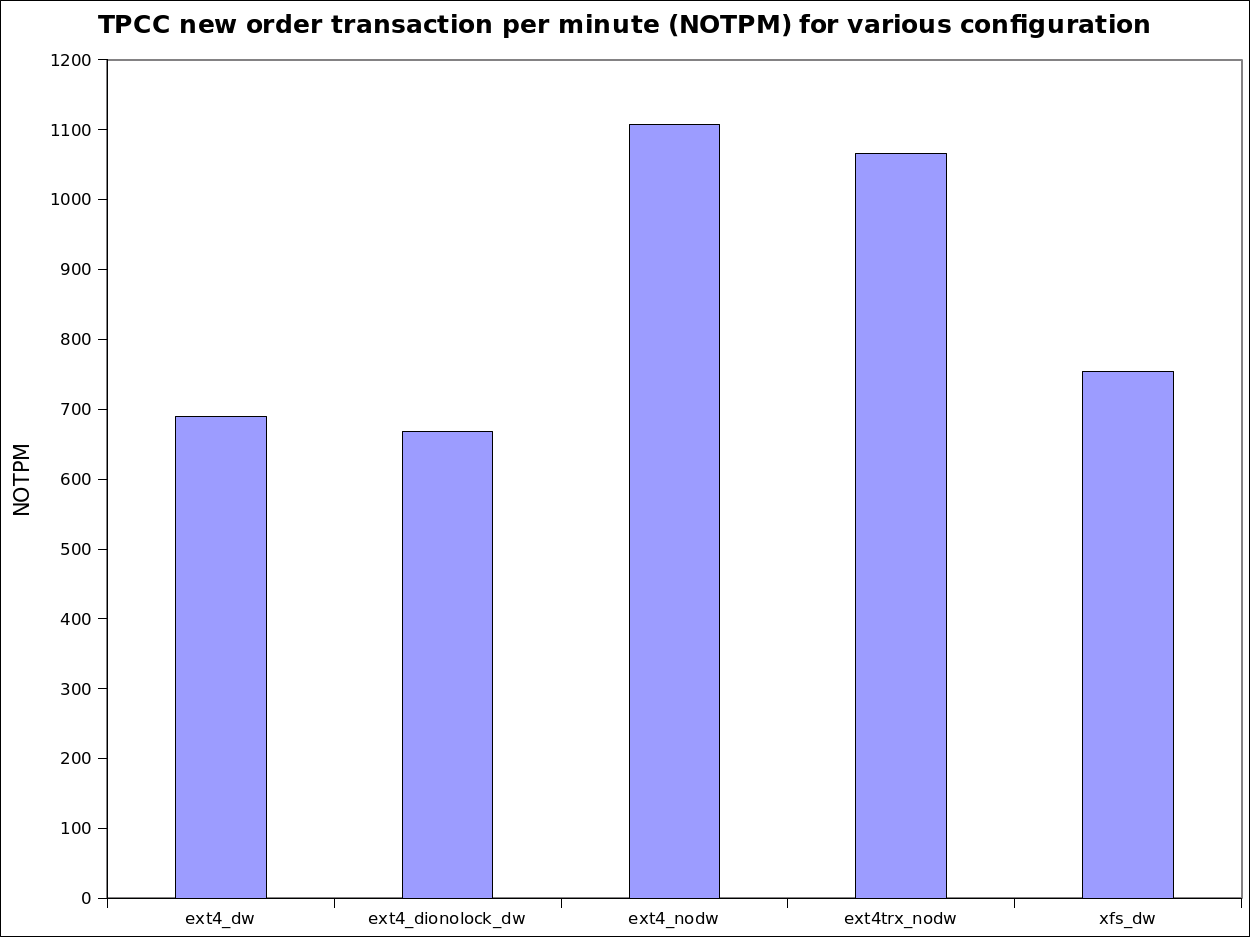
TPCC NOTPM for various configurations
In term of performance stability, you’ll find below a graphic of the per minute NOTPM output for three of the tests, ext4 non-transactional with the double write buffer, ext4 transactional without the double write buffer and xfs with the double write buffer. The dispersion is qualitatively similar for all three. The values presented above are just the averages of those data sets.
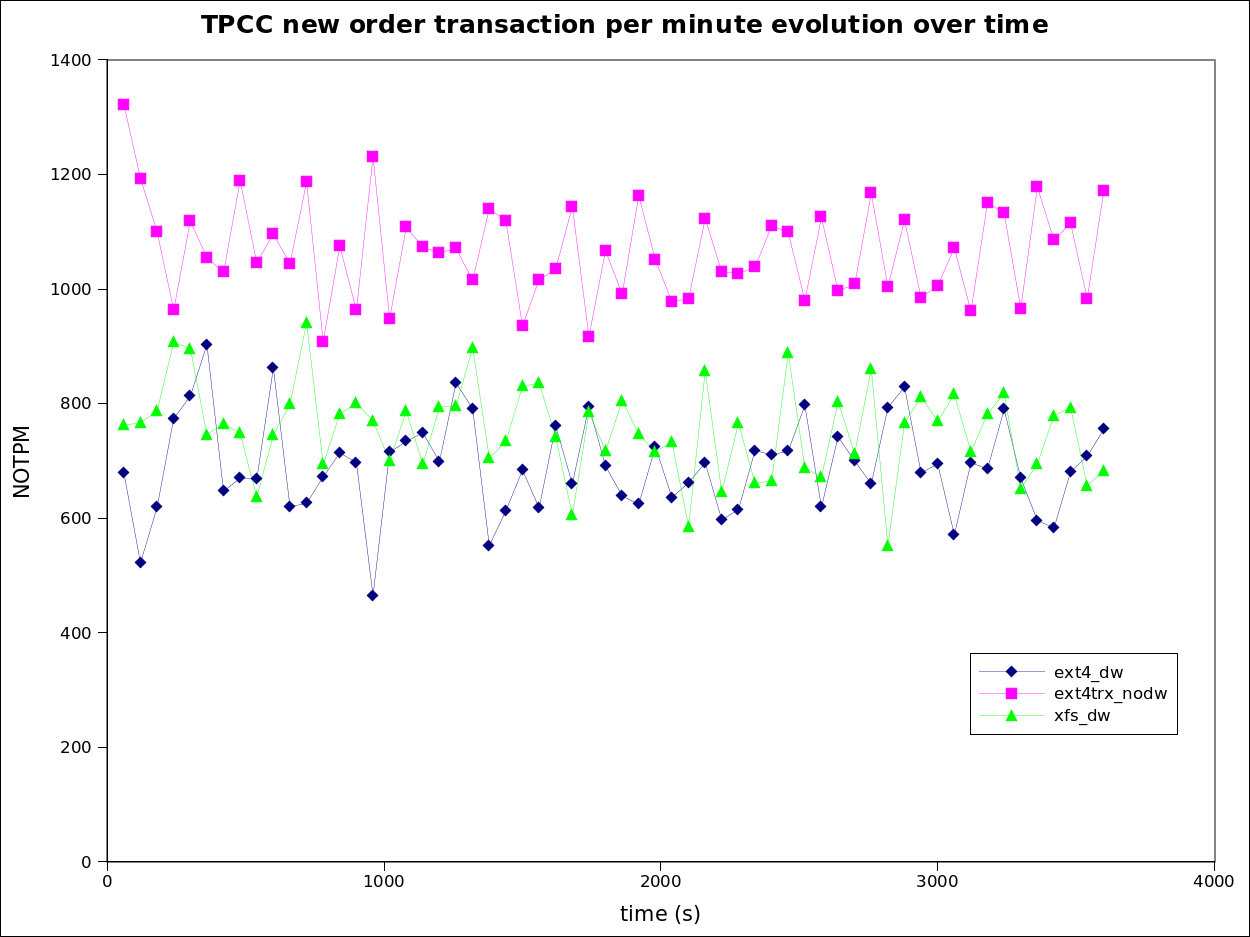
TPCC NOTPM evolution over time
Safety
Innodb data corruption is not fun and removing the innodb double write buffer is a bit scary. In order to be sure it is safe, I executed the following procedure ten times:
- Start mysql and wait for recovery and for the buffer pool load to complete
- Check the error log for no corruption
- start tpcc from another server
- After about 10 minutes, physically unplug the server
- Plug back and restart the server
I observed no corruption. I was still a bit preoccupied, what if the test is wrong? I removed the “data=journal” mount option and did a new run. I got corruption the first time. So given what the procedure I followed and the number of crash tests, I think it is reasonable to assume it is safe to replace the InnoDB double write buffer by the ext4 transactional journal.
I also looked at the kernel ext4 sources and changelog. Up to recently, before kernel 3.2, O_DIRECT wasn’t supported with data=journal and MySQL would have issued a warning in the error log. Now, with recent kernels, O_DIRECT is mapped to O_DSYNC and O_DIRECT is faked, always for data=journal, which is exactly what is needed. Indeed, I tried “innodb_flush_method = O_DSYNC” and found the same results. With older kernels I strongly advise to use the “innodb_flush_method = O_DSYNC” setting to make sure files are opened is a way that will cause them to be transactional for ext4. As always, test thoroughfully, I only tested on Ubuntu 14.04.
Impacts on MyISAM
Since we are no longer really using O_DIRECT, even if set in my.cnf, the OS file cache will be used for InnoDB data. If the database is only using InnoDB that’s not a big deal but if MyISAM is significantly used, that may cause performance issues since MyISAM relies on the OS file cache so be warned.
Fast SSDs
If you have a SSD setup that doesn’t offer a transactional file system like the FusionIO directFS, a very interesting setup would be to mix spinning drives and SSDs. For example, let’s suppose we have a mirror of spinning drives handled by a raid controller with a write cache (and a BBU) and an SSD storage on a PCIe card. To reduce the write load to the SSD, we could send the file system journal to the spinning drives using the “journal_path=path” or “journal_dev=devnum” options of ext4. The raid controller write cache would do an awesome job at merging the write operations for the file system journal and the amount of write operations going to the SSD would be cut by half. I don’t have access to such a setup but it seems very promising performance wise.
Conclusion
Like ZFS, ext4 can be transactional and replacing the InnoDB double write buffer with the file system transaction journal yield a 55% increase in performance for write intensive workload. Performance gains are also expected for SSD and mixed spinning/SSD configurations.






So if it is using the OS file cache, doesn’t that mean some unnecessary double buffering (once in the buffer pool, once in the OS cache)?
I was toying with an idea similar to yours with the RAID Controller and BBU, I was thinking of just putting the doublewrite buffer (and maybe innodb logs) onto the RAID controller, perhaps just attaching two small SSD. I may post again once I have some hardware available.
If someone were to come up with a sort of PCIe Ramdisk with a BBU (or better, capacitors) at a competitive price, that would be a great alternative to RAID controllers, especially since the CoW filesystems like ZFS and btrfs usually also implement RAID in software.
What is the perf benefit for a system with HW RAID and battery backed write cache?
Did you try sending the double-buffer to a separate disk drive or SSD? Just wondering if the double-buffer sync-ing on the same drive as the main database is causing lots of head thrashing. (I don’t have deep MySQL specific experience, but this was a problem on another system. Giving the write-ahead buffer a separate drive helped.)
Yves,
The question I have in this case – do we know why does it happen ? Did you have a chance to check the amount of writes going to device in this case ?
Here is what puzzles me. As I understand ZFS simply stores the new data in the new location, hence it only needs to update meta-data to show where the new data is located.
EXT4 with data=journal is I understand correctly just stores data in the journal as well as storing it in location where it should be, so it still should double amount of writes as Innodb does.
If I’m correct when do not we have some problem in how doublewrite buffer is implemented in Innodb – I do not see big reason why filesystem should be able to do it a lot more efficiently. Or has design of data=journal changed in EXT4 ?
I also wonder whenever results for SSDs and RAID with BBU are the same as this is where you can get dramatic differences as any “sync” is very expensive on conventional hard drives and it is much cheaper on system with BBU or SSD.
@MarkC: If you send the ext4 journal to a file on an array behind a raid controller with a write cache and a BBU, it may actually never be written to disk and stay in the write cache memory since the max journal size with 4KB pages is 400MB. In such a case, spinning disks will even be faster than SSDs.
@Alan: The issue with the double write buffer is really internal to MySQL, those 64 pages are running hot and force some kind of serialization.
@Peter: My explanation to this is the serialization effect of the double-write buffer, in order to use some of the 64 pages in it, a thread must wait for the write operation of another thread to complete its write to the data file. I did measure the amount of writes in both cases and yes, they are the same but the ext4 journal seems to better handle concurrency. As of testing with SSDs and a raid controller with BBU, I’d love to do that, any hardware I could use for a few hours?
Hi Yves,
your results are looking very promising!! thanks for sharing!
I’m also curious if using O_DSYNC instead of the “classic” O_DIRECT for RW workloads will not bring any other impact within other tests cases…
then, indeed, this EXT4 data journaling is not solving the issue with “double amount of data written”.. – however, keeping in mind arriving to the market various HW solutions for “battery protected memory” (even small amount, but if 400MB is already enough then it’ll look more than attractive, and “double write amount” will be completely avoided and keep a longer life for flash storage ;-))
the only point with this EXT4 feature remains unclear for me: will EXT4 really guarantee the absense of partially written pages?.. (keeping in mind that EXT4 is operating with 4K, while InnoDB default is 16K, and EXT4 knows just nothing about InnoDB data, so for EXT4 “commited” 2 pages of 4K will remain safe, while there will be still 2 other pages “not comitted” and breaking a 16K page for InnoDB).. — any idea?..
and, yes, regarding generally the “double-write buffer” feature – its main bottleneck on a fast storage will be its own kind of serialization due implementation design.. One of the solutions could be here to have several such buffers (ex. one per BP instance) to increase the throughput (while the issue with twice written data will still remain); or bypass the “buffer” and let each page double write go independently to others, etc..
while the best solution could be probably to have just a single write but on a different place, but I’m not sure at the end we’ll really have less IO writes 😉
or the best of the best is simply to avoid double write buffer completely by involving atomic writes, but unfortunately currently it’s available only on Fusion-io and not yet a common standard..
Rgds,
-Dimitri
Re-send :
Hi Yves,
your results are looking very promising!! thanks for sharing!
I’m also curious if using O_DSYNC instead of the “classic” O_DIRECT
for RW workloads will not bring any other impact within other tests
cases…
then, indeed, this EXT4 data journaling is not solving the issue with
“double amount of data written”.. – however, keeping in mind arriving
to the market various HW solutions for “battery protected memory”
(even small amount, but if 400MB is already enough then it’ll look
more than attractive, and “double write amount” will be completely
avoided and keep a longer life for flash storage ;-))
the only point with this EXT4 feature remains unclear for me: will
EXT4 really guarantee the absense of partially written pages?..
(keeping in mind that EXT4 is operating with 4K, while InnoDB default
is 16K, and EXT4 knows just nothing about InnoDB data, so for EXT4
“commited” 2 pages of 4K will remain safe, while there will be still 2
other pages “not comitted” and breaking a 16K page for InnoDB).. —
any idea?..
and, yes, regarding generally the “double-write buffer” feature – its
main bottleneck on a fast storage will be its own kind of
serialization due implementation design.. One of the solutions could
be here to have several such buffers (ex. one per BP instance) to
increase the throughput (while the issue with twice written data will
still remain); or bypass the “buffer” and let each page double write
go independently to others, etc..
while the best solution could be probably to have just a single write
but on a different place, but I’m not sure at the end we’ll really
have less IO writes 😉
or the best of the best is simply to avoid double write buffer
completely by involving atomic writes, but unfortunately currently
it’s available only on Fusion-io and not yet a common standard..
Rgds,
-Dimitri
Hi Dimitri,
When you use O_SYNC or O_DSYNC, if you do a 16KB write operation with data=journal, it is transactional, you can’t have a fraction of 16KB written. It is the exact same principle has transaction in a database. Best way to convince yourself is to try 🙂 I did many many tests recently. I am trying to get hold on server with raid_ctrl/BBU/spinning and a PCIe SSD card. I’ll redo the benchmarks splitting the journals (ext4 and innodb) on spinning drives and datafile on SSD.
Regards,
Yves
Hi Yves,
great then if it’s so!..
(and means I have to replay all my test with the following options as well ;-))
Rgds,
-Dimitri
I may have access soon to a system with a RAID Controller, BBU and a combination of SSD (only SATA though) and HDD. I will run a few tests with different combinations of log, data, doublewrite etc. location.
Interestingly, there is already a controller for a PCIe based RAM drive that backs up into Flash, the IDT 89HF08P08AG3 [1]. Seems like nobody so far built a device based on it.
[1] http://www.techpowerup.com/171760/idt-announces-worlds-first-pci-express-gen-3-nvme-nv-dram-controller.html
Just a follow-up to this post, I tried it on a busy system and there was a rather peculiar effect where the system would just stall at a determinable (is that a word?) moment. The result was a single MySQLd process hogging 100% of one CPU and every other thread stalling. This didn’t happen with data=writeback and I think I have isolated the problem to this mount option. Use caution.
@Nils: I pushed quite hard on the server I tested and I never saw that behavior. I may also get access to a server with a raid ctrl, bbu and fusion io card, can you tell me more about your setup so that I can try to reproduce your results.
We found something *amazing* with EXT4.
If you disable journaling on EXT4 with
tune2fs -O "^has_journal" /dev/, our TPS according to sysbench increased from a terrible 10/sec to 600/sec. This is on a soft raid of 2 7.2k HDD drives with 10GB innodb buffer.Disabling double-write only increased the old figure to 20/sec, which is nothing.
Before disabling journaling, iotop showed:
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
28511 be/3 root 0.00 B/s 0.00 B/s 0.00 % 96.30 % [jbd2/md2-8]
31172 be/4 mysql 3.89 K/s 50.58 K/s 0.00 % 22.05 % mysqld
31215 be/4 mysql 7.78 K/s 54.48 K/s 0.00 % 16.12 % mysqld
Where jbd2/md2-8 (the journalling engine) caused most of the waiting on io.
Here’s our OLTP sysbench test with journaling on EXT4:
*Enabled journalling, double=buffer=0, O_DIRECT*
OLTP test statistics:
queries performed:
read: 0
write: 5805
other: 2322
total: 8127
transactions: 1161 (19.33 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 5805 (96.63 per sec.)
other operations: 2322 (38.65 per sec.)
And after disabling it:
*Disabled journalling on drive, double-buffer=0*
OLTP test statistics:
queries performed:
read: 0
write: 274820
other: 109928
total: 384748
transactions: 54964 (916.05 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 274820 (4580.24 per sec.)
other operations: 109928 (1832.10 per sec.)
Gopi Aravind: disabling journaling destroys durability, methinks.
https://www.percona.com/blog/2014/05/23/improve-innodb-performance-write-bound-loads/
@Yves Trudeau Trudeau
I have the same result as Nils.
CentOS 6.6, 30 Gb of RAM, Intel Xeon E5-2680 v2 @ 2.80GHz. Percona-Server-55-5.5.42-rel37.1.el6.x86_64
It’s EC2 instance on AWS. Mysql datadir has mounted on raid0 with 2 provisioned ssd volumes with 1800 IOPS total. According to the sysbench results – with data=journal performance are dramatically decreased, on the stock kernel – 2.6.32-504.12.2.el6.x86_64
I have used the following my.cnf config
thread_cache_size = 16
innodb_thread_concurrency = 0
innodb_buffer_pool_size = 12G
innodb_log_file_size = 512M
innodb_log_buffer_size = 64M
innodb_fast_shutdown = 0
innodb_read_io_threads = 32
innodb_write_io_threads = 32
innodb_flush_log_at_trx_commit=2
innodb_doublewrite=0/1
innodb_flush_method=O_DIRECT/O_DSYNC
And run the test with the following command
# sysbench –num-threads=16 –test=oltp –oltp-table-size=50000000 –oltp-test-mode=complex –mysql-engine=innodb –mysql-db=sysbench –mysql-user=sysbench –mysql-password=7654321 –db-driver=mysql –max-requests=0 –max-time=3600 run
******* kernel-2.6.32-504.12.2.el6.x86_64 *******
noatime,nodiratime,data=journal + innodb_doublewrite=0 + innodb_flush_method=O_DSYNC
OLTP test statistics:
queries performed:
read: 16338434
write: 5835151
other: 2334061
total: 24507646
transactions: 1167030 (324.17 per sec.)
deadlocks: 1 (0.00 per sec.)
read/write requests: 22173585 (6159.26 per sec.)
other operations: 2334061 (648.34 per sec.)
http://imgur.com/2ZSpN1N
On the kernel-3.19 from ELRepo there si no difference at all
kernel-ml-3.19.3-1.el6.elrepo.x86_64
noatime,nodiratime,data=ordered + innodb_doublewrite=0 + innodb_flush_method=O_DIRECT
OLTP test statistics:
queries performed:
read: 150480764
write: 53743130
other: 21497252
total: 225721146
transactions: 10748626 (2985.73 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 204223894 (56728.78 per sec.)
other operations: 21497252 (5971.45 per sec.)
http://imgur.com/bTBfYjL
noatime,nodiratime,data=ordered + innodb_doublewrite=1 + innodb_flush_method=O_DIRECT
OLTP test statistics:
queries performed:
read: 149974454
write: 53562305
other: 21424922
total: 224961681
transactions: 10712461 (2975.68 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 203536759 (56537.91 per sec.)
other operations: 21424922 (5951.36 per sec.)
http://imgur.com/1wmBwG2
noatime,nodiratime,data=journal + innodb_doublewrite=0 + innodb_flush_method=O_DIRECT
OLTP test statistics:
queries performed:
read: 147382788
write: 52636704
other: 21054682
total: 221074174
transactions: 10527340 (2924.26 per sec.)
deadlocks: 2 (0.00 per sec.)
read/write requests: 200019492 (55560.89 per sec.)
other operations: 21054682 (5848.51 per sec.)
http://imgur.com/FxISmjn
Did I miss something?
@alex, unless it has been backported, O_DIRECT is not supported by the kernel before 3.2, that’s why the last test performs well. Newer kernels maps to O_DSYNC.
Now, regarding the bad results for the first test, there have been a lot of changes to ext4 in the 3.0+ kernel era, could this be just a bad mutex that got fixed? I’ll try to reproduce you result on a Centos6 box, could you retry on your side on a more recent kernel, 3.2+ kernel.
Regards,
Yves
> I’ll try to reproduce you result on a Centos6 box, could you retry on your side on a more recent kernel, 3.2+ kernel.
Already. As I told before, I have tried kernel 3.10.73-1 and 3.19.3-1 from ELRepo. The max performance I got on 3.10.73-1 with the following settings
thread_cache_size = 16
innodb_buffer_pool_size = 12G
innodb_log_file_size = 2048M
innodb_log_buffer_size = 64M
innodb_fast_shutdown = 0
innodb_thread_concurrency = 0
innodb_read_io_threads = 64
innodb_write_io_threads = 64
innodb_flush_log_at_trx_commit=0
innodb_doublewrite=1
innodb_flush_method=O_DIRECT
innodb_additional_mem_pool_size = 64M
innodb_use_sys_malloc = 1
OLTP test statistics:
queries performed:
read: 172605426
write: 61644795
other: 24657918
total: 258908139
transactions: 12328959 (3424.71 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 234250221 (65069.44 per sec.)
other operations: 24657918 (6849.41 per sec.)
Test execution summary:
total time: 3600.0035s
total number of events: 12328959
total time taken by event execution: 57499.1132
per-request statistics:
min: 2.54ms
avg: 4.66ms
max: 21032.40ms
approx. 95 percentile: 5.58ms
Threads fairness:
events (avg/stddev): 770559.9375/1317.18
execution time (avg/stddev): 3593.6946/0.01
@alex: I have reproduced my results on 2 different servers (ubuntu 14.04 and Centos6 with 3.18 kernel) very easily but I struggled to reproduce yours. I finally succeeded partially using SSD storage. Apparently, SSD storage doesn’t stress the doublewrite buffer which kind of make sense. I’ll write a follow up post on the matter.
@Yves Trudeau, I am experiencing some poor write performance and came about this post. As per your last post, did you ever do any additional testing with SSD? Is it worth trying to disable it in that case?
I was thinking about turning the double write buffer in a MySQL instance that was set up with a 4 KB page size on top of an iSCSI storage with physical block size of 4 KB, but my colleagues are not so convinced this is a good idea due to other elements in the storage stack (Linux LVM, xfs). Any thoughts on that?
@Eduardo, the latest Percona Server 5.7 has the parallel doublewriter feature, it solves the contention issue with the doublewrite buffer