

In this blog, we’ll look at how to achieve better-than-linear scaling.
Scalability is the capability of a system, network or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth. For example, we consider a system scalable if it is capable of increasing its total output under an increased load when resources (typically hardware) are added: https://en.wikipedia.org/wiki/Scalability.
It is often accepted as a fact that systems (in particular databases) can’t scale better than linearly. By this I mean when you double resources, the expected performance doubles, at best (and often is less than doubled).
We can attribute this assumption to Amdahl’s law (https://en.wikipedia.org/wiki/Amdahl%27s_law), and later to the Universal Scalability Law (http://www.perfdynamics.com/Manifesto/USLscalability.html). Both these laws prescribe that it is impossible to achieve better than linear scalability. To be totally precise, this is practically correct for single server systems when the added resources are only CPU units.
Multi-nodes systems
However, I think databases systems no longer should be seen as single server systems. MongoDB and Cassandra for a long time have had multi-node auto-sharding capabilities. We are about to see the rise of strongly-consistent SQL based multi-node systems. And even MySQL is frequently deployed with manual sharding on multi-nodes.
The products like Vitess (http://vitess.io/) proposes auto-sharding for MySQL, and with ProxySQL (which I will use in my experiment) you can setup a basic sharding schema.
I describe multi-nodes setups, because in this environment it is possible to achieve much better than linear scalability. I will show this below.
Why is this important?
Understanding scalability of multi-node systems is important for resource planning, and understanding how much of a potential performance gain we can expect when we add more nodes. This is especially interesting for cloud deployments.
How is it possible?
I’ve written about how the size of available memory (cache) affects the performance. When we add additional nodes to the deployment, effectively we increase not only CPU cores, but also the memory that comes with the node (and we are adding extra IO capacity). So, with increasing node counts, we also increase available memory (and cache). As we can see from these graphs, the effect of extra memory could be non-linear (and actually better than linear). Playing on this fact, we can achieve better-than-linear scaling in a sharded setup. I am going to show the experimental setup of how to achieve this.
Experimental setup
To show the sharded setup we will use ProxySQL in front of N MySQL servers (shards). We also will use sysbench with 60 tables (4 million rows each, uniform distribution).
- For one shard, this shard contains all 60 tables
- For two shards, each shard contains 30 tables each
- For three shards, each shard contains 20 tables each
- …
- For six shards, each shard contains ten tables each
So schematically, it looks like this:
One shard:
Two shards:
Six shards:
We want to measure how the performance (for both throughput and latency) changes when we go from 1 to 2, to 3, to 4, to 5 and to 6 shards.
For the single shard, I used a Google Cloud instance with eight virtual CPUs and 16GB of RAM, where 10GB is allocated for the innodb_buffer_pool_size.
The database size (for all 60 tables) is about 51GB for the data, and 7GB for indexes.
For this we will use a sysbench read-only uniform workload, and ProxySQL helps to perform query routing. We will use ProxySQL query rules, and set sharding as:
mysql -u admin -padmin -h 127.0.0.1 -P6032 -e "DELETE FROM mysql_query_rules"
shards=$1
for i in {1..60}
do
hg=$(( $i % $shards + 1))
mysql -u admin -padmin -h 127.0.0.1 -P6032 -e "INSERT INTO mysql_query_rules (rule_id,active,username,match_pattern,destination_hostgroup,apply) VALUES ($i,1,'root','sbtest$is',$hg,1);"
done
mysql -u admin -padmin -h 127.0.0.1 -P6032 -e "LOAD MYSQL QUERY RULES TO RUNTIME;"
Command line for sysbench 1.0.4:
sysbench oltp_read_only.lua --mysql-socket=/tmp/proxysql.sock --mysql-user=root --mysql-password=test --tables=60 --table-size=4000000 --threads=60 --report-interval=10 --time=900 --rand-type=pareto run
The results
| Nodes | Throughput | Speedup vs. 1 node | Latency, ms |
| 1 | 245 | 1.00 | 244.88 |
| 2 | 682 | 2.78 | 87.95 |
| 3 | 1659 | 6.77 | 36.16 |
| 4 | 2748 | 11.22 | 21.83 |
| 5 | 3384 | 13.81 | 17.72 |
| 6 | 3514 | 14.34 | 17.07 |
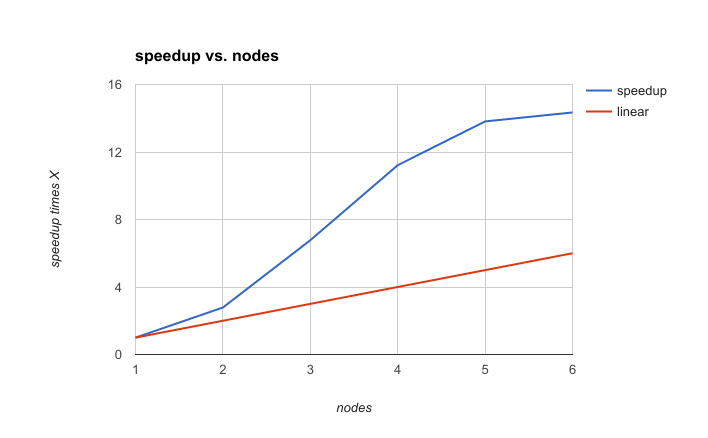
As we can see, the performance improves by a factor much better than just linearly.
With five nodes, the improvement is 13.81 times compared to the single node.
The 6th node does not add much benefit, as at this time data practically fits into memory (with five nodes, the total cache size is 50GB compared to the 51GB data size)
Factors that affects multi-node scaling
How can we model/predict the performance gain? There are multiple factors to take into account: the size of the active working set, the available memory size and (also importantly) the distribution of the access to the working set (with uniform distribution being the best case scenario, and with access to the one with only one row being the opposite corner-case, where speedup is impossible). Also we need to keep network speed in mind: if we come close to using all available network bandwidth, it will be impossible to get significant improvement.
Conclusion
In multi-node, auto-scaling, auto-sharding distributed systems, the traditional scalability models do not provide much help. We need to have a better framework to understand how multiple nodes affect performance.





I took your nodes/throughput/… table and added speedups when comparing a higher node count to the previous smaller one. Here are the results:
1 node=NOT APPLICABLE
2 nodes=2.78
3 nodes=2.43525179856115
4 nodes=1.65731166912851
5 nodes=1.23083778966132
6 nodes=1.03837798696597
As you can see, you get decreasing benefit from setting up mode nodes. 2 and 3 nodes are still a big improvement, and sorta the 4th node too, but after 4 nodes the benefit doesn’t increase so much with each added node. That’s likely cuz the per-node allocation ain’t big enough for this load.
Neil Gunther, the author of the USL, wrote a paper about superlinear scaling (in Hadoop) and has worked on modeling it for years. The USL does model and explain it as-is.
Does this at all account for joins across tables that exist on different backend servers?