

 While I was working on my grFailOver POC, I have also done some additional parallel testing. One of them was to see how online DDL is executed inside a Group Replication cluster.
While I was working on my grFailOver POC, I have also done some additional parallel testing. One of them was to see how online DDL is executed inside a Group Replication cluster.
The online DDL feature provides support for instant and in-place table alterations and concurrent DML. Checking the Group Replication (GR) official documentation, I was trying to identify if any limitation exists, but the only thing I have found was this:
“Concurrent DDL versus DML Operations. Concurrent data definition statements and data manipulation statements executing against the same object but on different servers is not supported when using multi-primary mode. During execution of Data Definition Language (DDL) statements on an object, executing concurrent Data Manipulation Language (DML) on the same object but on a different server instance has the risk of conflicting DDL executing on different instances not being detected.”
This impacts only when you have a multi-primary scenario, which is NOT recommended and not my case. So, in theory, GR should be able to handle the online DDL without problems.
My scenario:
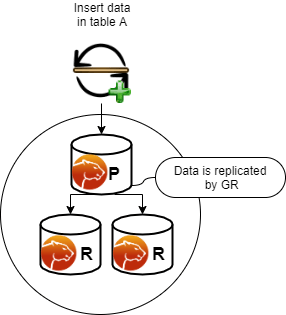
I have two DCs and I am going to do actions on my DC1 and see how it propagates all over, and what impact it will have.
The Test
To do the test, I will run and insert from select.
1 | insert into windmills_test select null,uuid,millid,kwatts_s,date,location,active,time,strrecordtype from windmills7 limit 1; |
And a select, on my Primary node gr1, while on another connection execute the ALTER:
1 | ALTER TABLE windmills_test ADD INDEX idx_1 (`uuid`,`active`), ALGORITHM=INPLACE, LOCK=NONE; |
As you may have noticed, I am EXPLICITLY asking for INPLACE and lock NONE. So in this case, MySQL cannot satisfy; it should exit and not execute the command.
In the meantime, on all other nodes, I will run a check command to see WHEN my ALTER is taking place. Let us roll the ball:
On my Primary, the command to insert the data:
1 | [root@gr1 grtest]# while [ 1 = 1 ];do da=$(date +'%s.%3N');/opt/mysql_templates/mysql-8P/bin/mysql --defaults-file=./my.cnf -uroot -D windmills_s -e "insert into windmills_test select null,uuid,millid,kwatts_s,date,location,active,time,strrecordtype from windmills7 limit 1;" -e "select count(*) from windmills_s.windmills_test;" > /dev/null;db=$(date +'%s.%3N'); echo "$(echo "($db - $da)"|bc)";sleep 1;done |
Again on Primary another session to execute the ALTER:
1 | DC1-1(root@localhost) [windmills_s]>ALTER TABLE windmills_test ADD INDEX idx_1 (`uuid`,`active`), ALGORITHM=INPLACE, LOCK=NONE; |
On other nodes to monitor when ALTER will start:
1 | while [ 1 = 1 ];do echo "$(date +'%T.%3N')";/opt/mysql_templates/mysql-8P/bin/mysql --defaults-file=./my.cnf -uroot -D windmills_s -e "show processlist;"|grep -i "alter";sleep 1;done |
What Happens
Data is inserted by the loop.
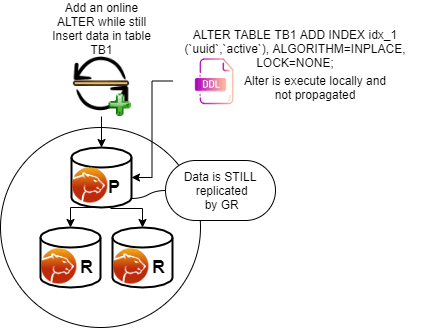
ALTER starts, but I can still insert data in my table, and most importantly, the data is propagated to all nodes of the DC1 cluster.
No ALTER action on the other nodes.
1 2 3 4 5 6 7 8 9 | .559 .502 .446 .529 .543 .553 .533 .602 .458 <---- end of the alter locally |
Once ALTER is complete on the local node (Primary) it is then executed (broadcast) to all the nodes participating in the cluster.
1 | [ERROR 1205 (HY000) at line 1: Lock wait timeout exceeded; try restarting transaction <--- waiting for waiting for handler commit No INSERTS are allowed |
But writes are suspended, waiting for:
1 | 37411 | root | localhost | windmills_s | Query | 19 | Waiting for table metadata lock | insert into windmills_test select null,uuid,millid,kwatts_s,date,location,active,time,strrecordtype |
And eventually, it will timeout.
The other point is that any write hangs until the slowest node had applied the ALTER. It is important to note that all nodes, not only the PRIMARY, remain pending waiting for the slow node: the slowest drives all.
GR3:
1 2 | 11:01:28.649 48 system user windmills_s Query 171 altering table ALTER TABLE windmills_test ADD INDEX idx_1 (`uuid`,`active`), ALGORITHM=INPLACE, LOCK=NONE 11:01:29.674 48 system user windmills_s Query 172 waiting for handler commit ALTER TABLE windmills_test ADD INDEX idx_1 (`uuid`,`active`), ALGORITHM=INPLACE, LOCK=NONE |
GR2:
1 2 | Start 11:00:14.438 18 system user windmills_s Query 97 altering table ALTER TABLE windmills_test ADD INDEX idx_1 (`uuid`,`active`), ALGORITHM=INPLACE, LOCK=NONE Ends 11:02:00.107 18 system user windmills_s Query 203 altering table ALTER TABLE windmills_test ADD INDEX idx_1 (`uuid`,`active`), ALGORITHM=INPLACE, LOCK=NONE |
Finally, when the last node in the GR cluster has applied the ALTER, the writes will resume, and the Replica node on DC2 will start its ALTER operation on PRIMARY first, then on the other nodes.
Summarizing:
- Writes are executed on Primary
- ALTER is executed on the Primary
- DDL does not impact the write operation and respects the not blocking directive.
- ALTER is completed on Primary and passed to all nodes
- Meta lock is raised on nodes
- ALL cluster waits for the slowest node to complete
- When all is done in the DC1 then the action is replicated to DC2
- Goto point 2
Conclusion
It seems that at the moment we have partial coverage of the online ddl feature when using group_replication. Of course, to have to wait for the SECONDARY nodes is better and less impacting than to wait for PRIMARY first and then the SECONDARIES.
But it is confusing, given I was expecting to have either full online coverage (I had explicitly asked for that in the DDL command) or a message telling me it cannot be executed online. Of course, I would prefer to have FULL online coverage. ;0)
Keep in mind my setup was also pretty standard and that changing group_replication_consistency does not affect the outcome. But not sure I can classify this as a bug, more an unexpected undesirable behavior.






Marco, thanks for this information! I’m curious: what happens if the migration completes on the PRIMARY, and one second later you kill the PRIMARY? Meaning, secondaries both began to run the replicated ALTER, but are blocking INSERTs. So, if you kill the PRIMARY, do all writes make it to the secondaries and will be eventually applied, or are INSERTs lost?
Interesting question, I will comeback to you later with an answer. Did not track that specific one.
Shlomi,
Results:
After Primary had complete the local operation the SECONDARY nodes start the alter.
– Write is on hold on Primary
– Kill primary
– SECONDARY NODES not able to elect Primary while applying the ALTER locally.
– Writes is still locked (NO PRimary elected)
– First SECONDARY complete the ALTER and BECOME PRIMARY, but remain locked by metalock
– Second Secondary complete ALTER
– Lock is raised
– Writes continue.
So we have still the lock but DATA inserted during the ONLINE segment on Primary is replicated correctly, then table is modified on SECONDARY nodes as expected and cluster continue without problems.
Thank you Marco! So, the system is leaderless for the duration of the ALTER on secondaries, because none of the secondaries would step up as primary, until all (both?) of them complete the ALTER, if I understand correctly. Meaning, if a 10 hour ALTER completes on the primary, the next 10 hours are an availability risk: if the primary goes down during those next 10 hours, the system is effectively read-only, again, if I understand correctly. Super interesting!
Correct.
Anyhow from the tests I did, the fastest secondary will become Primary. But then wait for the metalock given the remaining secondary is still processing.
Thanks for sharing!
I respectfully disagree though, for me this is no doubt a bug.
It should at least be documented and a warning raised…
Hope it could be solved in the future, adding indexes is fairly common.
Ivan, if you refer to the fact we do not get an error when specifically asking for “ALGORITHM=INPLACE, LOCK=NONE” then I agree. We should get a message saying the Onlne DDL cannot be executed following our request.
Said that the way DDL is processed (ONLINE on the primary) then LOCK has it’s own logic and is in a way better than TOI we have with Galera.
In any case I would love to have the ONLINE respected also on SECONDARY, but I will defer to Oracle about this.
Finally always keep in mind that to avoid this behaviour we can use PT-OSC (PT Online Schema CHange) as we have to do for incompatible changes. That will reduce the locking to a “moment” as usual.
Thanks for reading the blog