

 Last month I performed a review of the Percona Operator for MySQL Server which is still Alpha. That operator is based on Percona Server for MySQL and uses standard asynchronous replication, with the option to activate semi-synchronous replication to gain higher levels of data consistency between nodes.
Last month I performed a review of the Percona Operator for MySQL Server which is still Alpha. That operator is based on Percona Server for MySQL and uses standard asynchronous replication, with the option to activate semi-synchronous replication to gain higher levels of data consistency between nodes.
The whole solution is composed as:

Additionally, Orchestrator (https://github.com/openark/orchestrator) is used to manage the topology and the settings to enable on the replica nodes, the semi-synchronous flag if required. While we have not too much to say when using standard Asynchronous replication, I want to write a few words on the needs and expectations of the semi-synchronous (semi-sync) solution.
A Look into Semi-Synchronous
Difference between Async and Semi-sync.
Asynchronous:
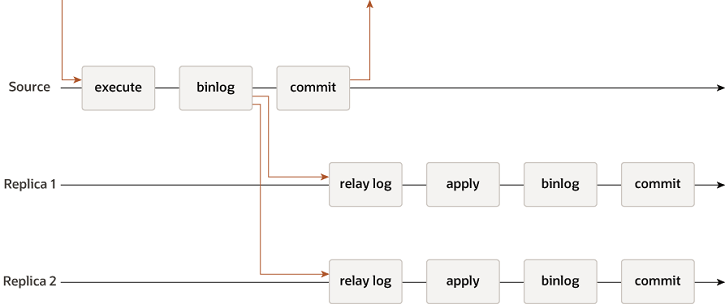
The above diagram represents the standard asynchronous replication. This method is expected by design, to have transactions committed on the Source that are not present on the Replicas. The Replica is supposed to catch up when possible.
It is also important to understand that there are two steps in replication:
- Data copy, which is normally very fast. The Data is copied from the binlog of the Source to the relay log on the Replica (IO_Thread).
- Data apply, where the data is read from the relay log on the Replica node and written inside the database itself (SQL_Thread). This step is normally the bottleneck and while there are some parameters to tune, the efficiency to apply transactions depends on many factors including schema design.
Production deployments that utilize the Asynchronous solution are typically designed to manage the possible inconsistent scenario given data on Source is not supposed to be on Replica at commit. At the same time, the level of High Availability assigned to this solution is lower than the one we normally obtain with (virtually-)synchronous replication, given we may need to wait for the Replicate to catch up on the gap accumulated in the relay-logs before performing the fail-over.
Semi-sync:
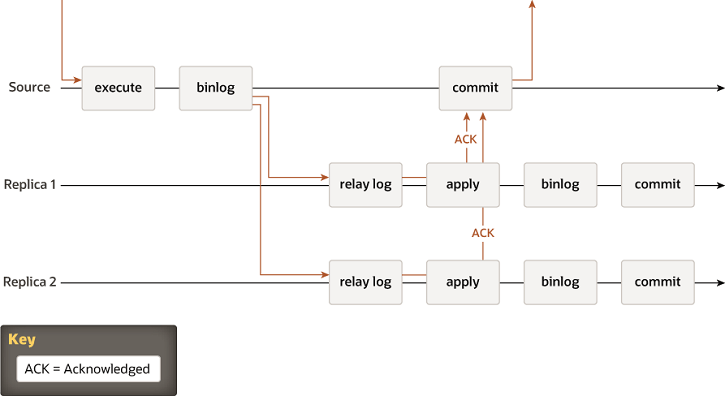
The above diagram represents the Semi-sync replication method. The introduction of semi-sync adds a checking step on the Source before it returns the acknowledgment to the client. This step happens at the moment of the data-copy, so when the data is copied from the Binary-log on Source to the Relay-log on Replica.
This is important, there is NO mechanism to ensure a more resilient or efficient data replication, there is only an additional step, that tells the Source to wait a given amount of time for an answer from N replicas, and then return the acknowledgment or timeout and return to the client no matter what.
This mechanism is introducing a possible significant delay in the service, without giving a 100% guarantee of data consistency.
In terms of availability of the service, when in presence of a high load, this method may lead the Source to stop serving the request while waiting for acknowledgments, significantly reducing the availability of the service itself.
At the same time, the only acceptable setting for rpl_semi_sync_source_wait_point is AFTER_SYNC (default) is because: In the event of source failure, all transactions committed on the source have been replicated to the replica (saved to its relay log). An unexpected exit of the source server and failover to the replica is lossless because the replica is up to date.
All clear? No? Let me simplify the thing.
- In standard replication, you have two moments (I am simplifying)
- Copy data from Source to Replica
- Apply data in the Replica node
- There is no certification on the data applied about its consistency with the Source
- With asynchronous the Source task is to write data in the binlog and forget
- With semi-sync, the Source writes the data on binlog and waits T seconds to receive an acknowledgment from N servers about them having received the data.
To enable semi-sync you follow these steps: https://dev.mysql.com/doc/refman/8.0/en/replication-semisync-installation.html
In short:
- Register the plugins
- Enable Source rpl_semi_sync_source_enabled=1
- Enable Replica rpl_semi_sync_replica_enabled = 1
- If replication is already running STOP/START REPLICA IO_THREAD
And here starts the fun, be ready for many “wait whaaat?”.
What are the T and N I have just mentioned above?
Well, the T is a timeout that you can set to avoid having the source wait forever for the Replica acknowledgment. The default is 10 seconds. What happens if the Source waits for more than the timeout? 
rpl_semi_sync_source_timeout controls how long the source waits on a commit for acknowledgment from a replica before timing out and reverting to asynchronous replication.
Careful of the wording here! The manual says SOURCE, so it is not that MySQL revert to asynchronous, by transaction or connection, it is for the whole server.
Now analyzing the work-log (see https://dev.mysql.com/worklog/task/?id=1720 and more in the references) the Source should revert to semi-synchronous as soon as all involved replicas are aligned again.
However, checking the code (see https://github.com/mysql/mysql-server/blob/beb865a960b9a8a16cf999c323e46c5b0c67f21f/plugin/semisync/semisync_source.cc#L844 and following), we can see that we do not have a 100% guarantee that the Source will be able to switch back.
Also in the code:
But, it is not that easy to detect that the replica has caught up. This is caused by the fact that MySQL’s replication protocol is asynchronous, meaning that if the source does not use the semi-sync protocol, the replica would not send anything to the source.
In all the run tests, the Source was not able to switch back. In short, Source was moving out from semi-sync and that was forever, no rollback. Keep in mind that while we go ahead.
What is the N I mentioned above? It represents the number of Replicas that must provide the acknowledgment back.
If you have a cluster of 10 nodes you may need to have only two of them involved in the semi-sync, no need to include them all. But if you have a cluster of three nodes where one is the Source, relying on one Replica only, it is not really secure. What I mean here is that if you choose to be semi-synchronous to ensure the data replicates, having it enabled for one single node is not enough, if that node crashes or whatever, you are doomed, as such you need at least two nodes with semi-sync.
Anyhow, the point is that if one of the Replica takes more than T to reply, the whole mechanism stops working, probably forever.
As we have seen above, to enable semi-sync on Source we manipulate the value of the GLOBAL variable rpl_semi_sync_source_enabled.
However, if I check the value of rpl_semi_sync_source_enabled when the Source shift to simple Asynchronous replication because of timeout:
select @@rpl_semi_sync_source_enabled;
1 2 3 4 5 6 | select @@rpl_semi_sync_source_enabled; +--------------------------------+ | @@rpl_semi_sync_source_enabled | +--------------------------------+ | 1 | +--------------------------------+ |
As you can see the Global variable reports a value of 1, meaning that semi-sync is active also if not.
In the documentation, it is reported that to monitor the semi-sync activity we should check for Rpl_semi_sync_source_status. Which means that you can have Rpl_semi_sync_source_status = 0 and rpl_semi_sync_source_enabled =1 at the same time.
Is this a bug? Well according to documentation:
When the source switches between asynchronous or semisynchronous replication due to commit-blocking timeout or a replica catching up, it sets the value of the Rpl_semi_sync_source_status or Rpl_semi_sync_master_status status variable appropriately. Automatic fallback from semisynchronous to asynchronous replication on the source means that it is possible for the rpl_semi_sync_source_enabled or rpl_semi_sync_master_enabled system variable to have a value of 1 on the source side even when semisynchronous replication is in fact not operational at the moment. You can monitor the Rpl_semi_sync_source_status or Rpl_semi_sync_master_status status variable to determine whether the source currently is using asynchronous or semisynchronous replication.
It is not a bug. However, because you documented it, it doesn’t change the fact this is a weird/unfriendly/counterintuitive way of doing, which opens the door to many, many possible issues. Especially given you know the Source may fail to switch semi-synch back.
Just to close this part, we can summarize as follows:
- You activate semi-sync setting a global variable
- Server/Source can disable it (silently) without changing that variable
- The server will never restore semi-sync automatically
- The way to check if semi-sync works is to use the Status variable
- When Rpl_semi_sync_source_status = 0 and rpl_semi_sync_source_enabled =1 you had a Timeout and Source is now working in asynchronous replication
- The way to reactivate semi-sync is to set rpl_semi_sync_source_enabled to OFF first then rpl_semi_sync_source_enabled = ON.
- Replicas can be set with semi-sync ON/OFF but unless you do not STOP/START the Replica_IO_THREAD the state of the variable can be inconsistent with the state of the Server.
What can go wrong?
Semi-Synchronous is Not Seriously Affecting the Performance
Others had already discussed semi-sync performance in better detail. However, I want to add some color given the recent experience with our operator testing.
In the next graphs, I will show you the behavior of writes/reads using Asynchronous replication and the same load with Semi-synchronous.
For the record, the test was a simple Sysbench-tpcc test using 20 tables, 20 warehouses, and 256 threads for 600 seconds.
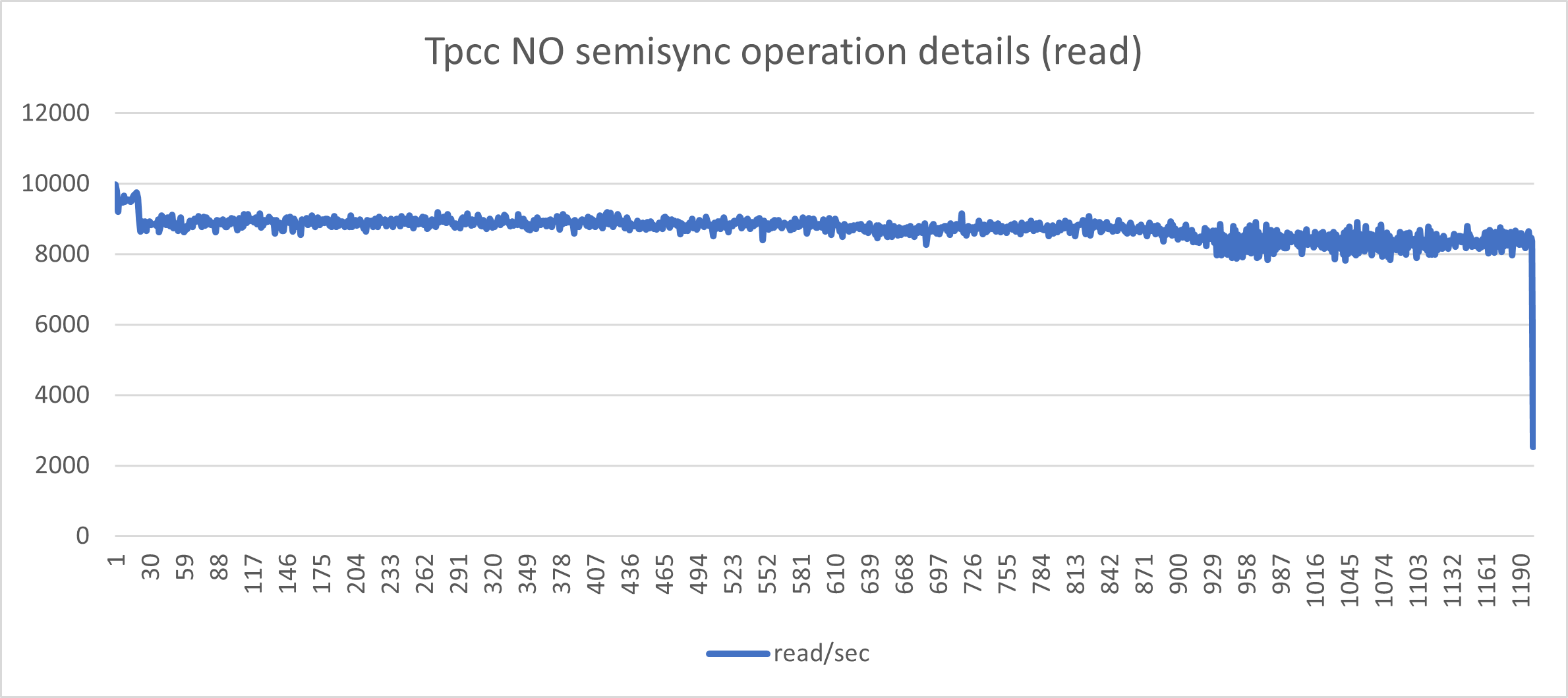
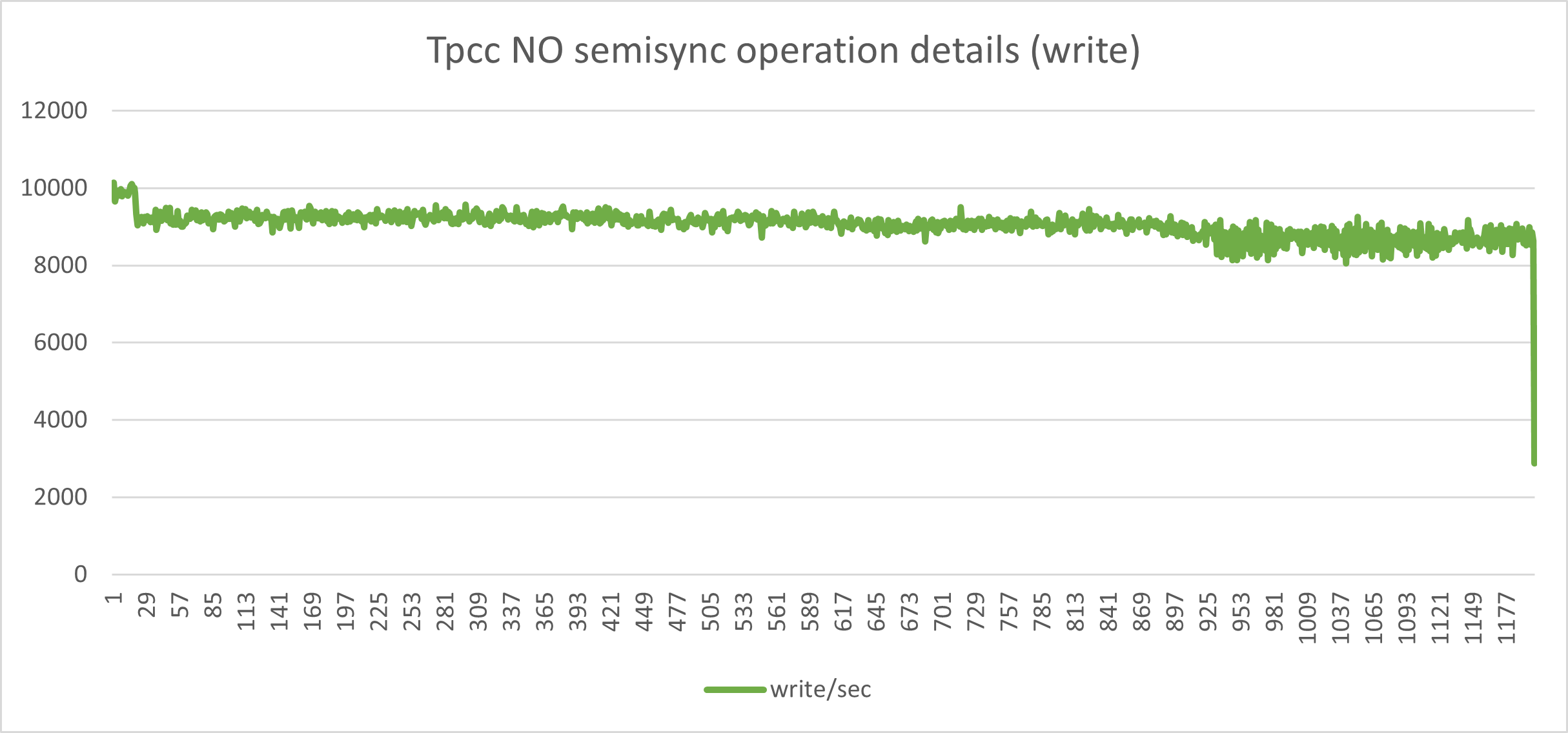
The one above indicates a nice and consistent set of load in r/w with minimal fluctuations. This is what we like to have.
The graphs below, represent the exact same load on the exact same environment but with semi-sync activated and no timeout.
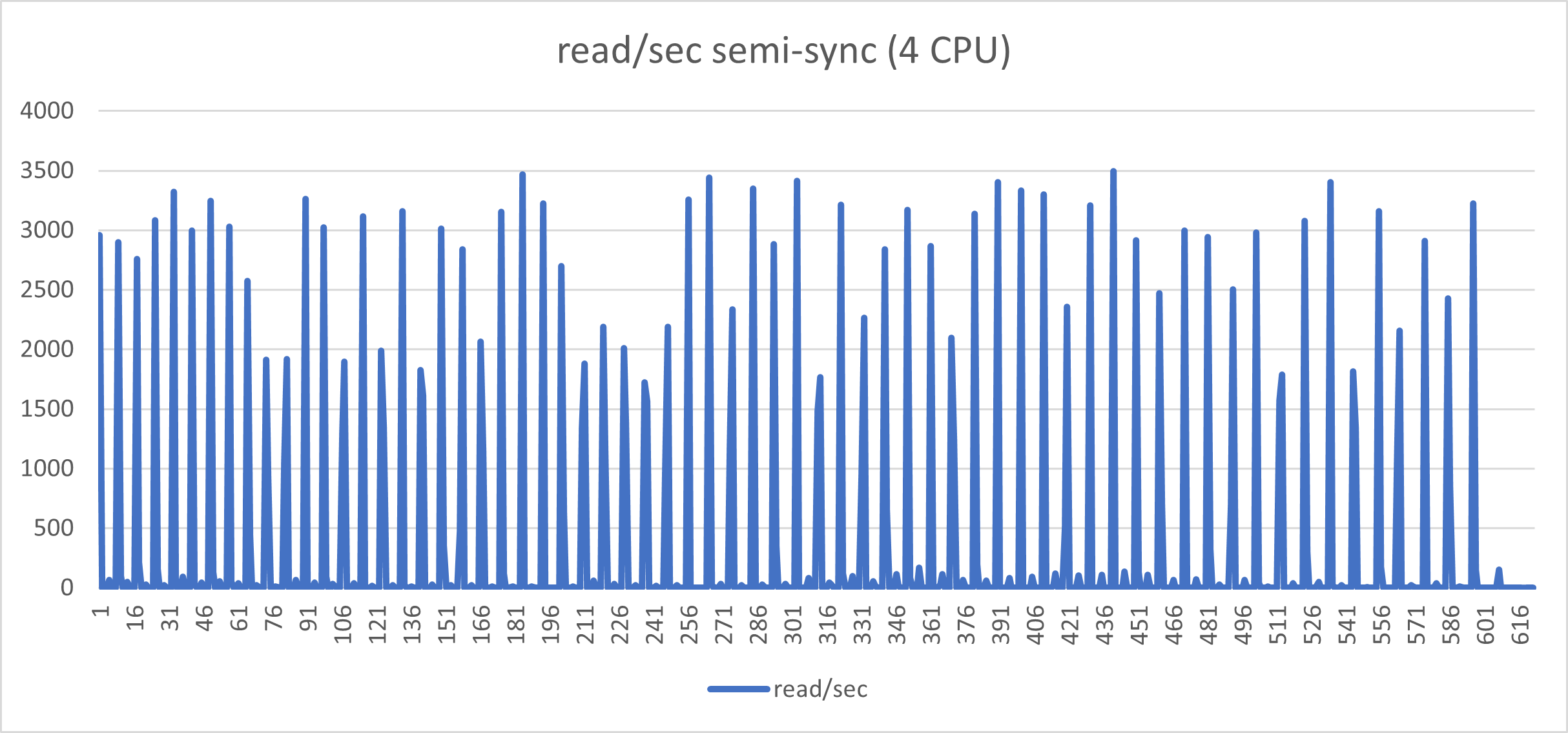
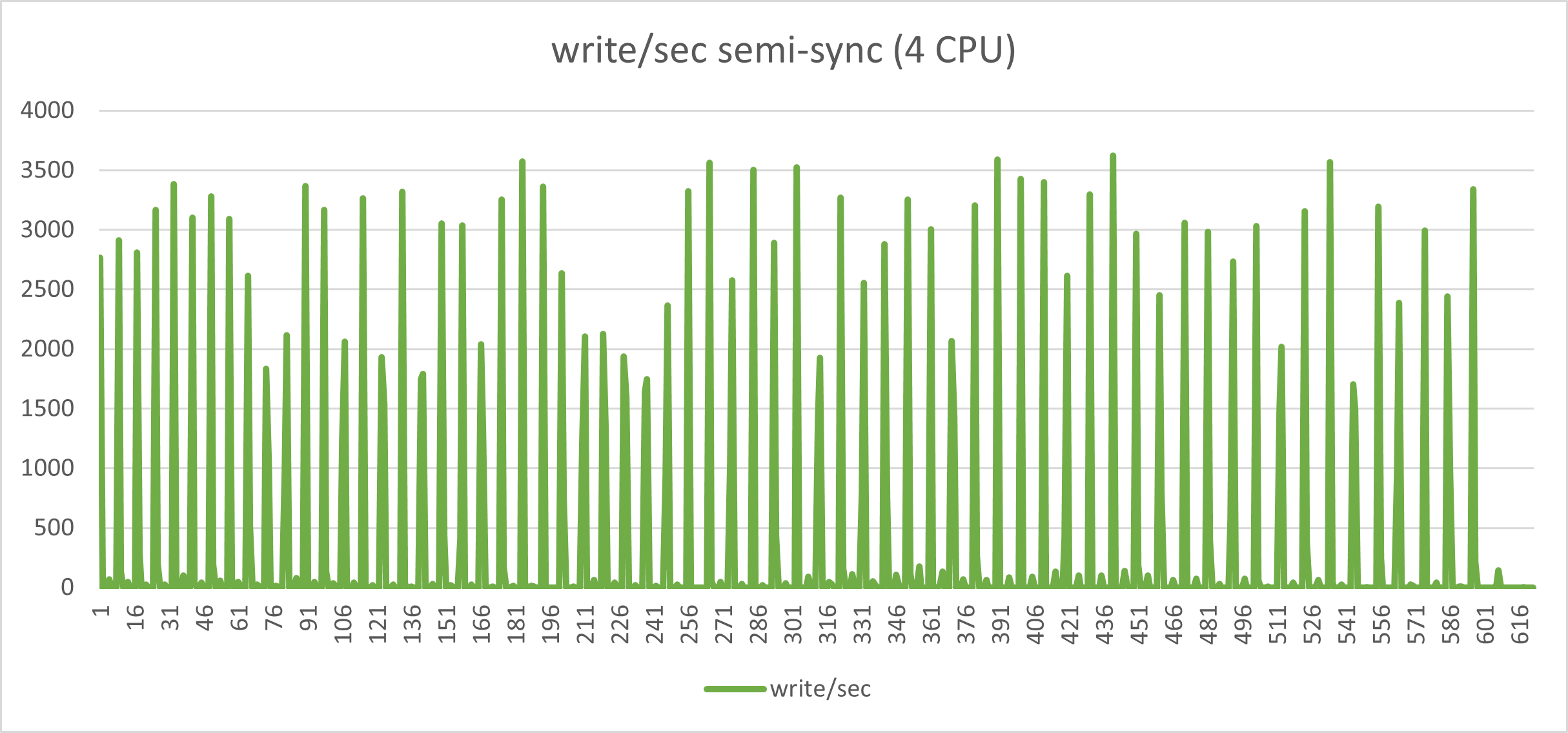
Aside from the performance loss (we went from Transaction 10k/s to 3k/s), the constant stop/go imposed by the semi-sync mechanism has a very bad effect on the application behavior when you have many concurrent threads and high loads. I challenge any serious production system to work in this way.
Of course, the results are in line with this yoyo game:
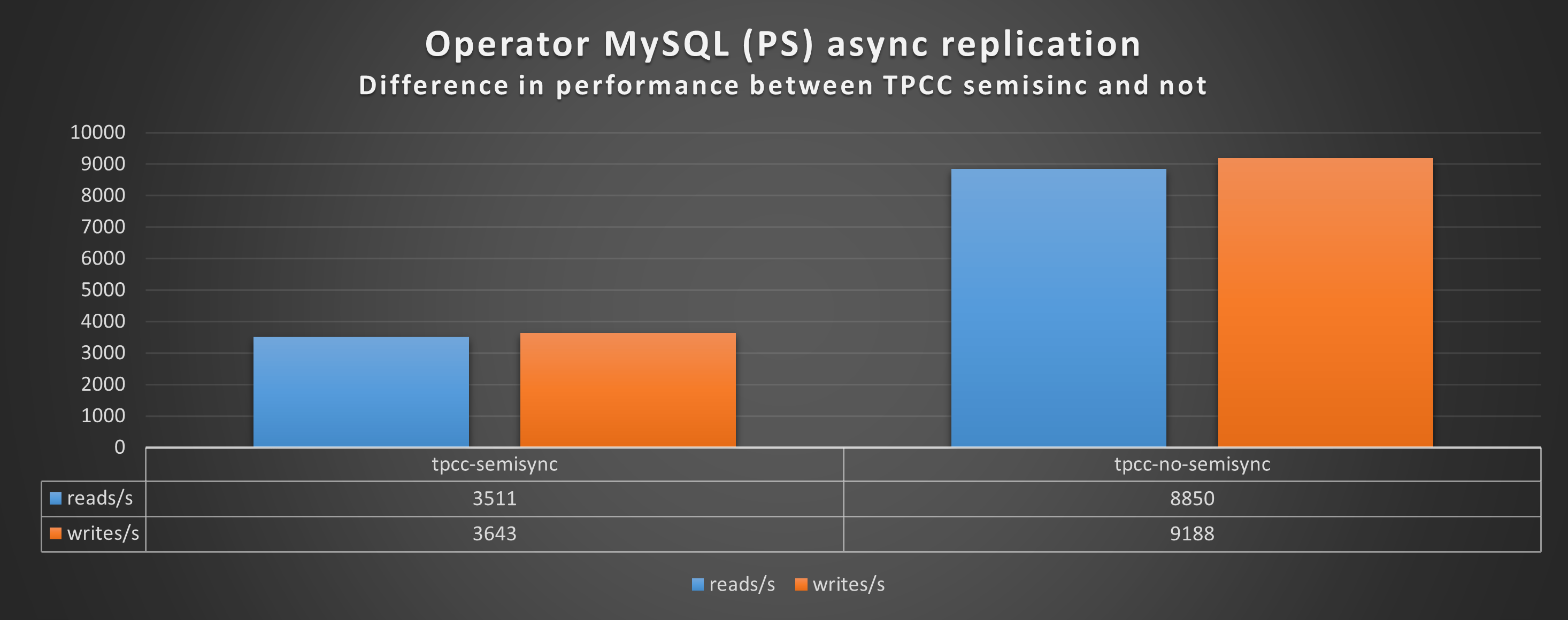
In the best case, when all was working as expected, and no crazy stuff happening, I had something around the 60% loss. I am not oriented to see this as a minor performance drop.
But at Least Your Data is Safe
As already stated at the beginning, the scope of semi-synchronous replication is to guarantee that the data in server A reaches server B before returning the OK to the application.
In short, given a period of one second, we should have minimal transactions in flight and limited transactions in the apply queue. While for standard replication (asynchronous), we may have … thousands.
In the graphs below we can see two lines:
- The yellow line represents the number of GTIDs “in-flight” from Source to destination, Y2 axes. In case of a Source crash, those transactions are lost and we will have data loss.
- The blue line represents the number of GTIDs already copied over from Source to Replica but not applied in the database Y1 axes. In case of a Source crash, we must wait for the Replica to process these entries, before making the node Write active, or we will have data inconsistency.
Asynchronous replication:
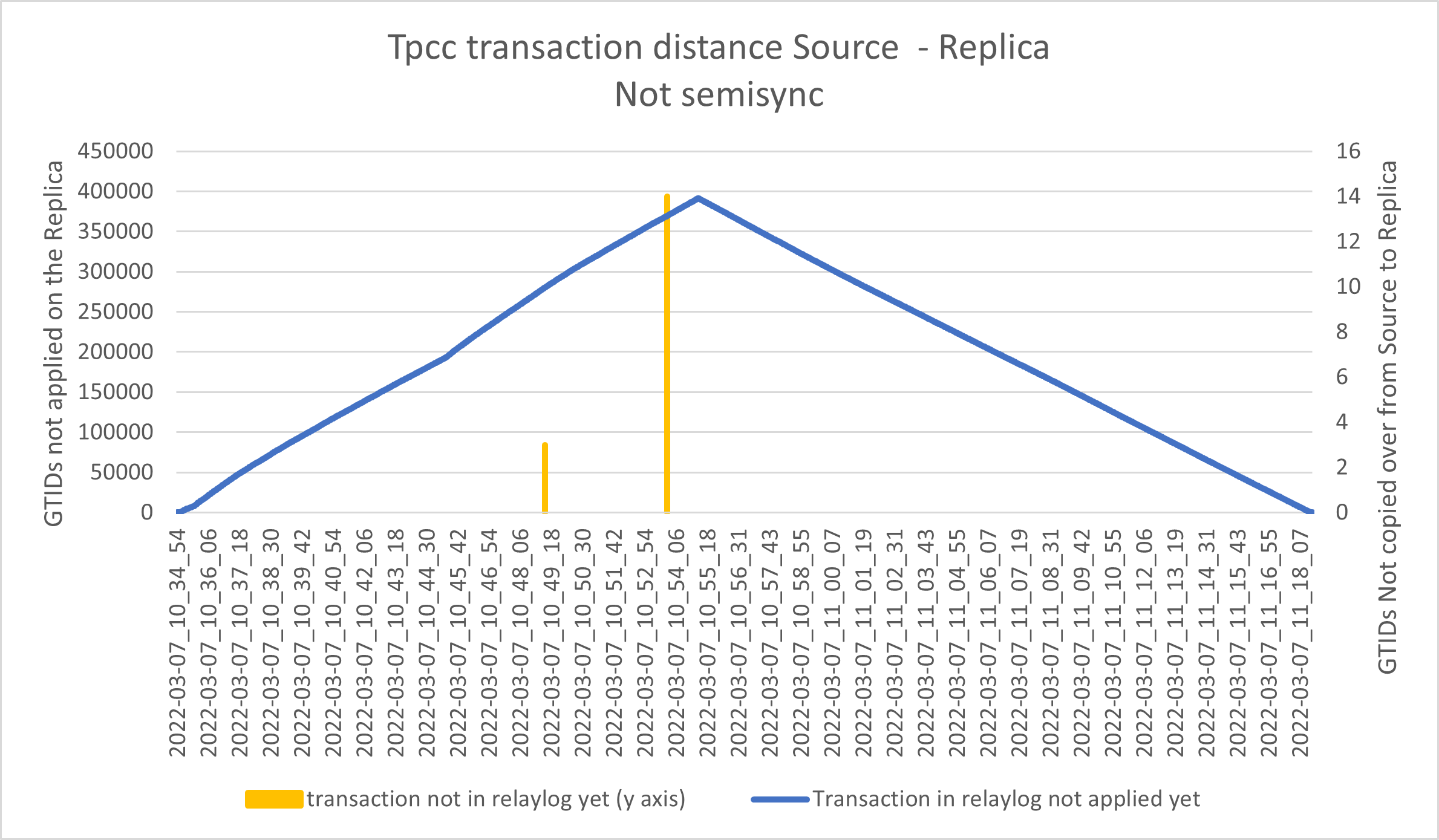
As expected we can see a huge queue in applying the transactions from relay-log, and some spike of transactions in flight.
Using semi-synchronous replication:
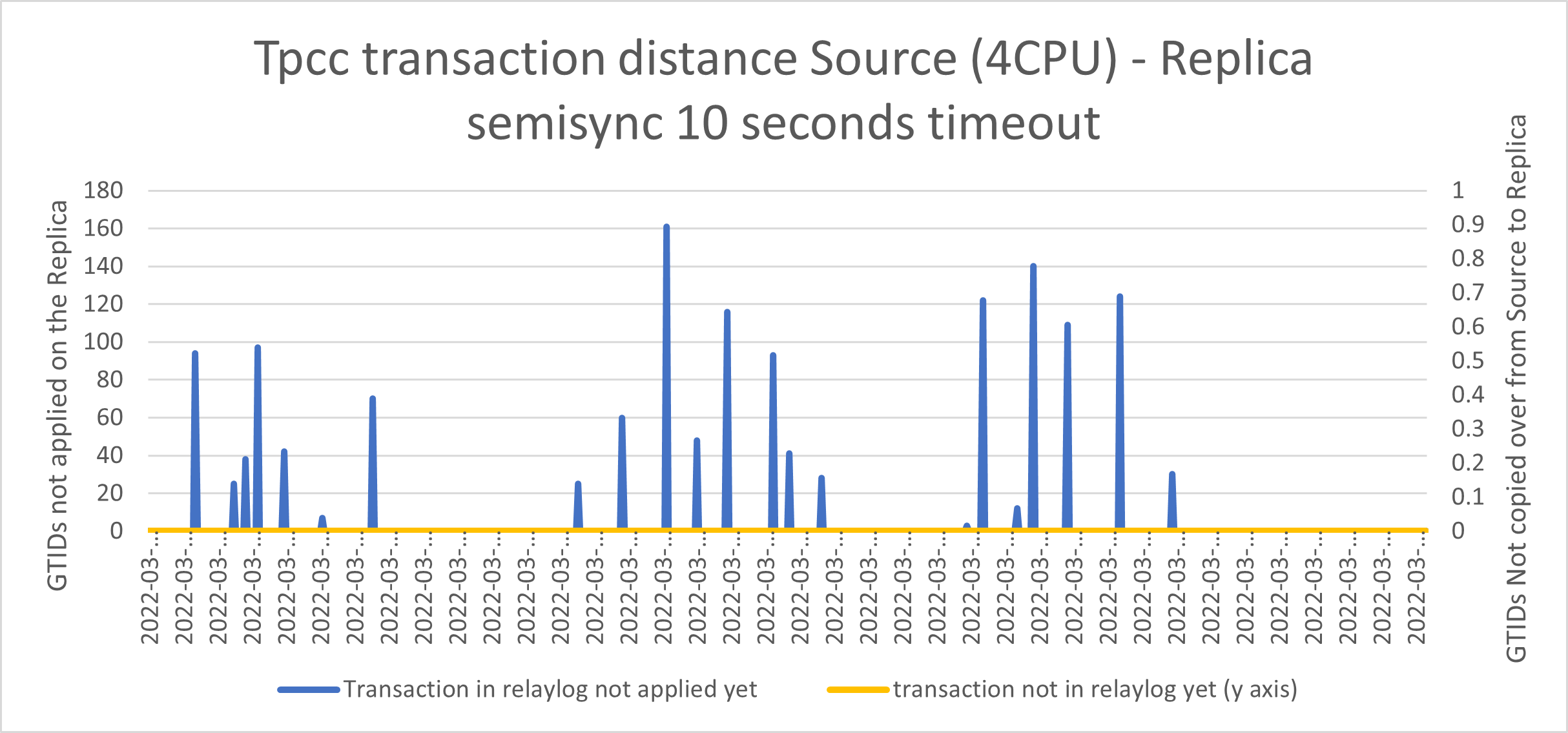
Yes, apparently we have reduced the queue and no spikes so no data loss.
But this happens when all goes as expected, and we know in production this is not the norm. What if we need to enforce the semi-sync but at the same time we cannot set the Timeout to ridiculous values like one week?
Simple, we need to have a check that puts back the semi-sync as soon as it is silently disabled (for any reason).
However doing this without waiting for the Replicas to cover the replication gap, cause the following interesting effects:
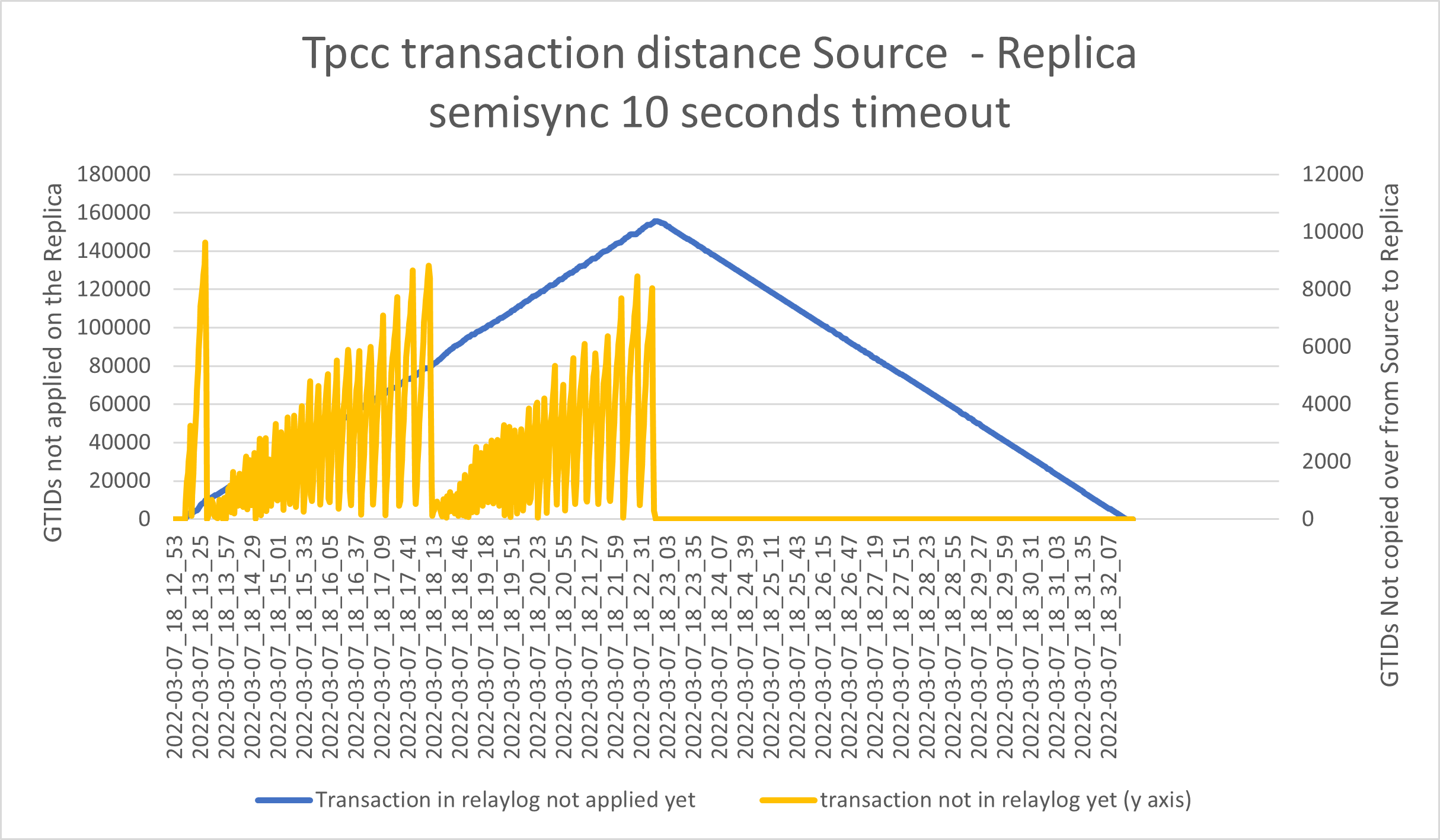
Thousands of transactions queued and shipped with the result of having a significant increase in the possible data loss and still a huge number of data to apply from the relay-log.
So the only possible alternative is to set the Timeout to a crazy value, however, this can cause a full production stop in the case a Replica hangs or for any reason, it disables the semi-sync locally.
Conclusion
First of all, I want to say that the tests on our operator using Asynchronous replication show a consistent behavior with the standard deployments in the cloud or premises. It has the same benefits, like better performance, and the same possible issues as a longer time to failover when it needs to wait for a Replica to apply the relay-log queue.
The semi-synchronous flag in the operator is disabled, and the tests I have done bring me to say “keep it like that!”. At least unless you know very well what you are doing and are able to deal with a semi-sync timeout of days.
I was happy to have the chance to perform these tests because they give me a way/time/need to investigate more on the semi-synchronous feature. Personally, I was not convinced about the semi-synchronous replication when it came out, and I am not now. I never saw a less consistent and less trustable feature in MySQL as semi-sync.
If you need to have a higher level of synchronicity in your database, just go for Group Replication, or Percona XtraDB Cluster, and stay away from semi-sync.
Otherwise, stay on Asynchronous replication, which is not perfect but it is predictable.
Explore the robust features of Percona XtraDB Cluster (PXC), a high availability and scalability solution for MySQL® clustering. Our datasheet provides an in-depth view of how PXC integrates Percona Server and Percona XtraBackup with the Codership Galera library to create a cost-effective, active/active MySQL high availability cluster. Discover how to enhance your database systems with a resilient and efficient clustering solution.

References
https://www.percona.com/blog/how-does-semisynchronous-mysql-replication-work/
https://www.percona.com/blog/percona-monitoring-and-management-mysql-semi-sync-summary-dashboard/
https://www.percona.com/blog/comparing-percona-xtradb-cluster-with-semi-sync-replication-cross-wan/
https://planetscale.com/blog/mysql-semi-sync-replication-durability-consistency-and-split-brains
https://dev.mysql.com/doc/refman/8.0/en/replication-semisync-installation.html
https://dev.mysql.com/worklog/task/?id=1720
https://dev.mysql.com/worklog/task/?id=6630






Thank you for the informative post Marco.
What is the performance difference between semi-synchronous and group replication?