

In Mo’ Data, Mo’ Problems, we explored the paradox that “Big Data” projects pose to organizations and how Tokutek is taking an innovative approach to solving those problems. In this post, we’re going to talk about another hot topic in IT, “The Cloud,” and how enterprises undertaking Cloud efforts often struggle with idea of “problem trading.” Also, for some reason, databases are just given a pass as traditionally “noisy neighbors” and that there is nothing that can be done about it. Lets take a look at why we disagree.
With the birth of the information age came a coupling of business and IT. Increasingly strategic business projects and objectives were reliant on information infrastructure to provide information storage and retrieval instead of paper and filing cabinets. This was the dawn of the database and what gave rise to companies like Oracle, Sybase and MySQL. With the appearance of true Enterprise Grade databases, companies now had the unprecedented ability to store huge volumes of information and parse it at speeds that were unthinkable even five years prior. This dramatically increased the quality and speed at which business decisions were made. However, reliance on IT came with a downside, the planning, design, procurement and implementation process often comprised a majority of the overall project timeline, often pushing out completion by, at least, 3 months and up to 24. Furthermore, the projectizing of IT resources was quickly leading to islands of compute, network and storage resources. These projectized islands were reducing the dollar per dollar effectiveness of IT, which is commonly a cost center, and making it the target of every CFO and CIO looking to boost their bottom line.
The “resource island” problem was the first one that innovative companies started solving. Technologies like Mainframe computing, Storage Area Networks (SAN) and, later, hardware abstracted virtualization (VMware ESX, Citrix Xen, et al) allowed resources to be grouped into logical pools and shared across many “machines.” Now, once stranded resources were being made available to other machines, increasing the effectiveness of every dollar of investment in the IT infrastructure. Furthermore, the speed at which infrastructure could be provisioned was dramatically increased. No longer did equipment need to be ordered & installed, it can be simply carved out of an existing pool of resources and the pool can be expanded at a later date. What once took well over three months to complete, could now be done in less than one week. This ability to pool resources and carve them up into containers is the first key enabler of “The Cloud.”
The second key enabler is profiling and orchestration. The idea here is that an organization would profile their workloads and determine the attributes that are common between the applications that they run. Once common attributes are identified, their attributes are distilled down into proifiles and used to orchestrate provisioning of resources from the logical pools based on the attributes identified during profiling. This is what people are describing when they use the term, “The Cloud.” If you want to actually see what this looks like, you can look at the machine profiles for AWS, Google or Microsoft. Once complete, users can order IT resources like they order lunch and they will be available in a matter of minutes.
Problem Trading
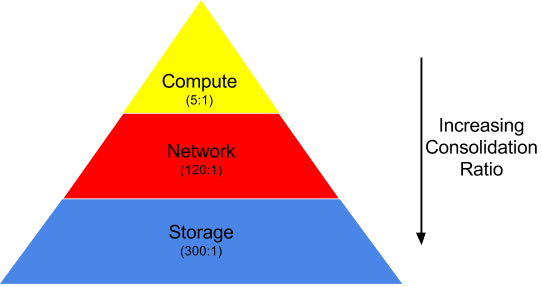
I know what you’re thinking, “sounds awesome…sign me up” and that’s why you feel queezy every time you hear “The Cloud;” it’s a wildly popular concept! Organizations are clamoring to increase the efficiency and agility of not only their IT org, but also their business. However, this model does have its drawbacks. This is what I meant when I used the term “problem trading;” trading efficiency and provisioning problems for the problems that consolidation brings (resource availability). As the consolidation ratio (efficiency) increases, which it does in Cloud environments, going “down the stack” (see below graphic) you have an increasingly difficult time ensuring that there are enough performance resources available for unexpected spikes. Oftentimes, this rears it’s ugly head at the storage level because it has the highest consolidation (greatest number of servers per storage array). Suddenly, a spike in the I/O workload for even 5% of your applications leads to everything on that storage array slowing down. This is the ugly side of the cloud; a Catch-22 situation between driving efficiency and resource contention. If you look at the enterprise storage array space, you will notice that there is another solid state disk based startup coming out of stealth mode every day; this is the new problem to solve. From capacity problems to performance problems.
I did take the time to explain the inception of the database market and all the benefits that it brought to business’. The reason for that is that databases tend to be the biggest talkers on any storage network and, also, the most sensitive to performance (latency) problems. Furthermore, databases underlie almost any application that people find useful and when they don’t perform, customer satisfaction decreases (either external or internal) . Would you be happy if it took 2 minutes between the time you hit “buy” for your Luggable Loo on Amazon (oh yes, a five gallon bucket can hold more than just joint compund) and the time you got your confirmation? I wouldn’t, and furthermore, Amazon would have never turned into the retail giant that they are today if that were the case.
What’s the Solution
Unfortunately, there’s is no single solution to the problem. An advanced IT organization will use a combination of headroom in resource pools, monitoring of performance trends, quality of service (QoS) and voodoo to fight off service interruption/degradation. However, at Tokutek, we believe that databases have an undeniable obligation to be better neighbors and that’s why we invented the Fractal Tree. It’s only natural for the software to evolve with the infrastructure. Like Ritalin to ADHD (Attention Deficit Hyperactivity Disorder), the Fractal Tree is the answer for the “storage hyperactive” database. As I quickly pointed out above, consolidation breeds contention and having many databases, who are firing thousands of IOPS (I/O operations, the basic unit of storage performance) at storage, becomes overwhelming and expensive. Think of it this way, Hitchcock references aside, being locked in a closet with a talkative crow would be annoying, but being locked in a closet with 100 would be unbearable. Making each crow 1/12th as loud would make the situation, while still challenging, much more manageable. That’s the value of the Fractal Tree, making the database the most efficient that it can be, all while offering accelerated performance. I understand that proof is in the putting, so I present the graphs at the bottom for your perusal. Simply put, 200M rows, or documents, are inserted into a database with iiBench running on AWS. The Fractal Tree inserts faster (first graph) and transfers less data (second graph) than traditional database indexing, all while consuming fewer resources. Distilled down, the Fractal Tree can accelerate workloads while making them a more thoughtful neighbor in highly consolidated environments.
What if a mechanic told you that they could easily increase your car’s mileage per gallon 90% while increasing its performance? Your first thought would probably be skeptical, and rightfully so. But, what if he offered to let you try it with no obligation…


Jon is the Lead Sales Engineer & Evangelist at Tokutek





